Когда IT-сфера столкнулась с необходимостью анализировать данные в таких объемах, с которыми никто никогда не работал, был создан ряд инструментов для работы с большими данными. Они впоследствии объединились в экосистему Hadoop.
Один из таких популярных инструментов — Apache Spark. Это платформа с открытым исходным кодом для реализации распределенной обработки больших данных. В отличие от классического обработчика из ядра Hadoop, реализующего двухуровневую концепцию MapReduce с хранением промежуточных данных на накопителях, Spark обрабатывает данные в оперативной памяти. Это значительно повышает скорость работы для некоторых классов задач.
В этой статье будут приведены различные решения по анализу рейтингов фильмов с помощью Apache Spark, который доступен в сервисах MapReduce Service (MRS) и Data Lake Insight (DLI) в облаке Advanced.
Постановка задачи
Необходимо получить cписок фильмов с рейтингом, например выше 4.0.
Ниже приведены исходные данные:
о фильмах
movieId
title
genres
1
Дьявол носит Prada (2006)
Комедия, драма
2
Однажды в… Голливуде (2019)
Комедия, драма
3
Шрек (2001)
Комедия, фэнтези
4
Бойцовский клуб (1999)
Триллер, драма
о рейтингах, которые пользователи поставили каждому фильму
userId
movieId
rating
timestamp
5
1
3.7
123456789
6
2
3.6
123456789
7
3
4.1
123456789
8
4
4.7
123456789
Получен список фильмов с рейтингом выше 4.0:
title | average_rating |
|---|---|
Шрек (2001) | 4.1 |
Бойцовский клуб (1999) | 4.7 |
Архив с файлами movies.csv и ratings.csv можно скачать по ссылке.
Способы решения задачи
Apache Spark в облаке Advanced доступен в сервисах MapReduce Service и Data Lake Insight в двух видах:
Spark SQL
Spark Submit
Задача будет решаться с помощью:
Spark SQL без написания кода программы. Этот способ может подойти пользователям, которые не уверены в своих навыках написания кода, но знают и понимают язык SQL.
Spark Submit с отдельно написанными короткими программами на Python. Этот способ будет ближе разработчикам.
В рамках этой лабораторной работы будут задействованы оба сервиса и два способа.
Перед началом работы
Создайте:
Кластер в MapReduce Service.
Очередь в сервисе Data Lake Insight.
Бакет в объектном хранилище Object Storage Service для хранения исходных данных и сохранения результатов рассчетов.
Создание кластера в MapReduce Service
MapReduce Service (MRS) — сервис для хранения, анализа и обработки больших данных. MRS предоставляет кластеры больших данных корпоративного уровня в облаке Advanced, в которых можно запускать компоненты больших данных, такие как Hadoop, Spark, HBase, Kafka и Storm. MRS полностью совместим со всеми open-source компонентами экосистемы.
Чтобы создать кластер в MapReduce Service:
Войдите в консоль управления Advanced:
В списке сервисов выберите MapReduce Service.
В правом верхнем углу нажмите Buy Cluster.
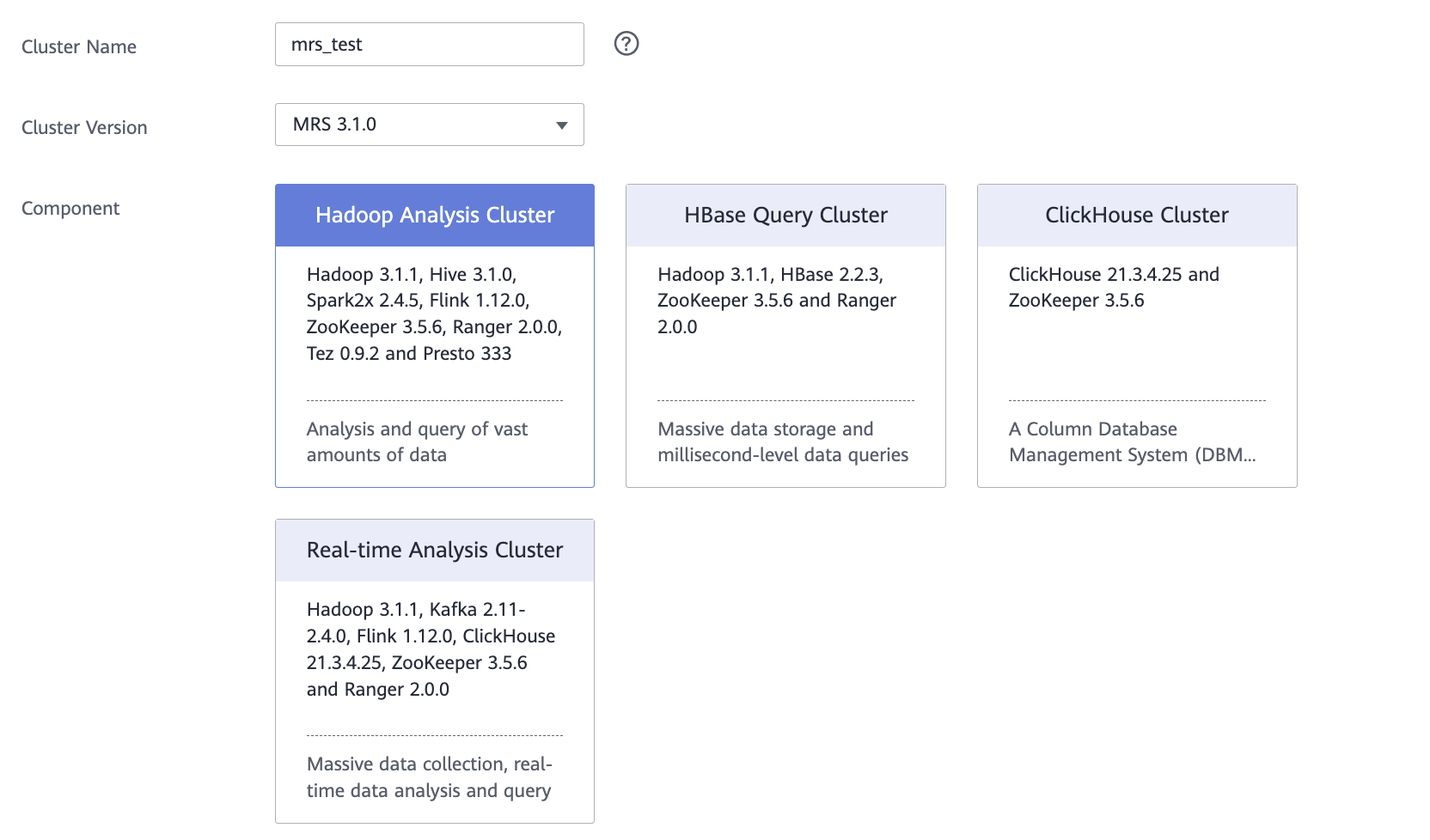
На вкладке Quick Config:
Cluster Name — укажите название кластера.
Cluster Version — выберите версию MRS 3.1.0.
Component — выберите компонент Hadoop Analysis Cluster.
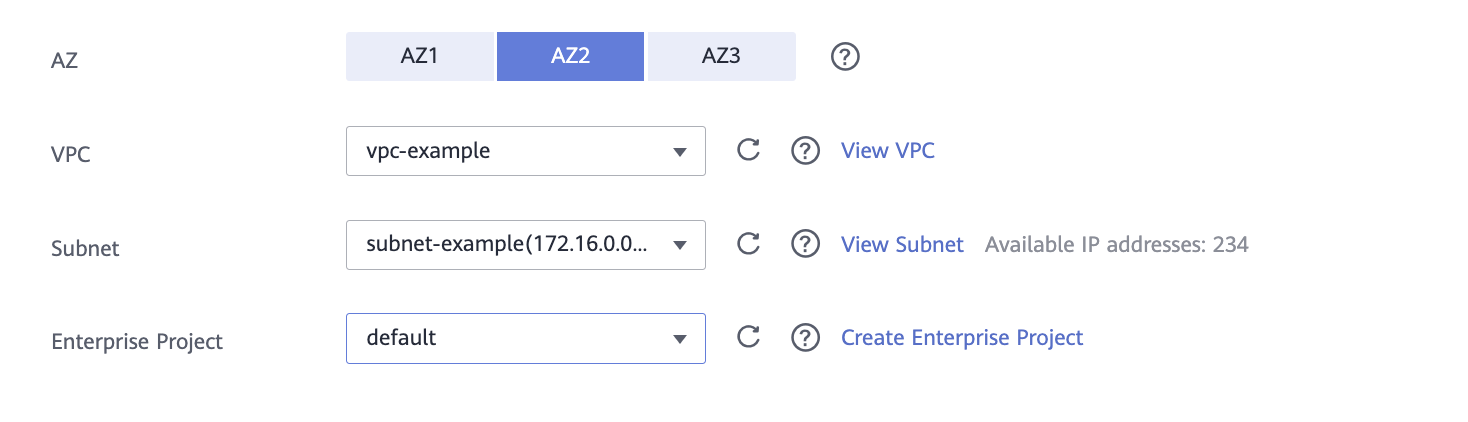
AZ — выберите зону доступности.
VPC — выберите виртуальную сеть или создайте новую.
Subnet — выберите подсеть или создайте новую.
Enterprise Project — выберите необходимый проект или default.
Cluster Node — нажав
 , можно выбрать самые простые виртуальные машины.
Для этой лабораторной работы много ресурсов не потребуется.
, можно выбрать самые простые виртуальные машины.
Для этой лабораторной работы много ресурсов не потребуется.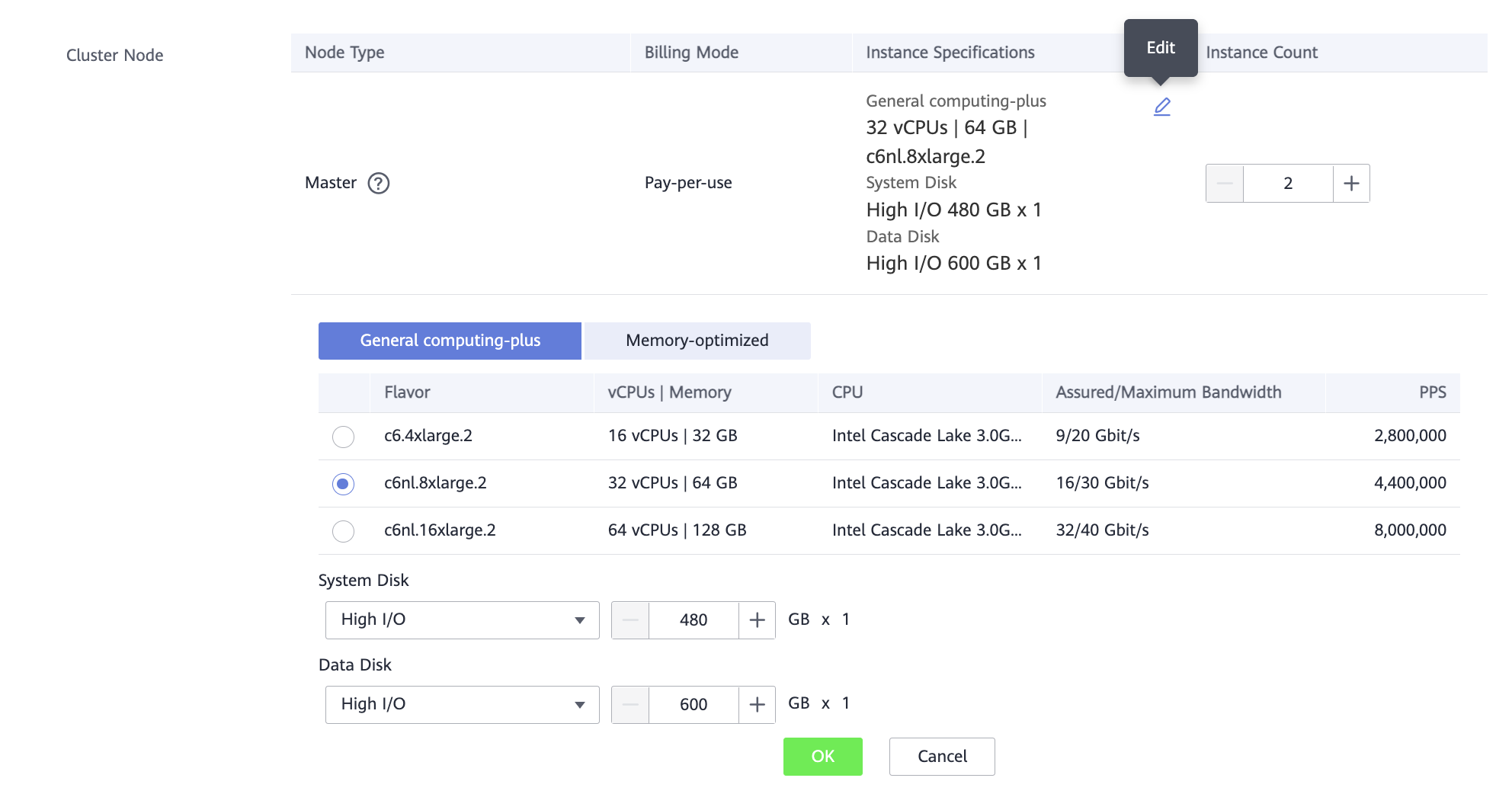
Password — задайте пароль для пользователя.
Confirm Password — подтвердите пароль.

Secure Communications — включите опцию.
Чтобы завершить создание, нажмите Buy Now.
Создание кластера занимает некоторое время. Успешная операция подтверждается статусом «Running».
Пока кластер создается, можно перейти к следующим подготовительным работам.
Создание очереди в Data Lake Insight
Data Lake Insight (DLI) — бессерверная технология для работы с большими данными в облаке.
В этой лабораторной работе необходимо создать очереди для Spark SQL и Spark Submit. Чтобы создать очередь:
Войдите в консоль управления Advanced:
В списке сервисов выберите Data Lake Insight.
В меню слева нажмите Queue Management.
В правом верхнем углу нажмите Buy Queue.
Задайте параметры:
Name — название очереди.
Queue Usage — выберите:
For General Purpose — для Spark Submit.
For SQL — для Spark SQL.
CU Specifications — 16 CUs.
Enterprise Project — выберите необходимый проект или default.
Чтобы завершить создание, нажмите Buy.
Нажмите ОК → Submit.
После создания очередь появится в списке на вкладке Queue Management.
Создание бакета OBS
Для того, чтобы загрузить файлы с исходными данными и сохранить результаты расчетов, нужно хранилище в облаке, доступное для используемых сервисов. В облаке Advanced есть сервис хранения и управления объектным хранилищем данных Object Storage Service (OBS).
Чтобы создать бакет в OBS:
Войдите в консоль управления Advanced:
В списке сервисов выберите Object Storage Service.
В правом верхнем углу нажмите Create Bucket.
Задайте параметры:
Data Redundancy Policy — для этой лабораторной работы выберите Single-AZ storage.
Bucket Name — название бакета.
Enterprise Project — выберите необходимый проект или default.
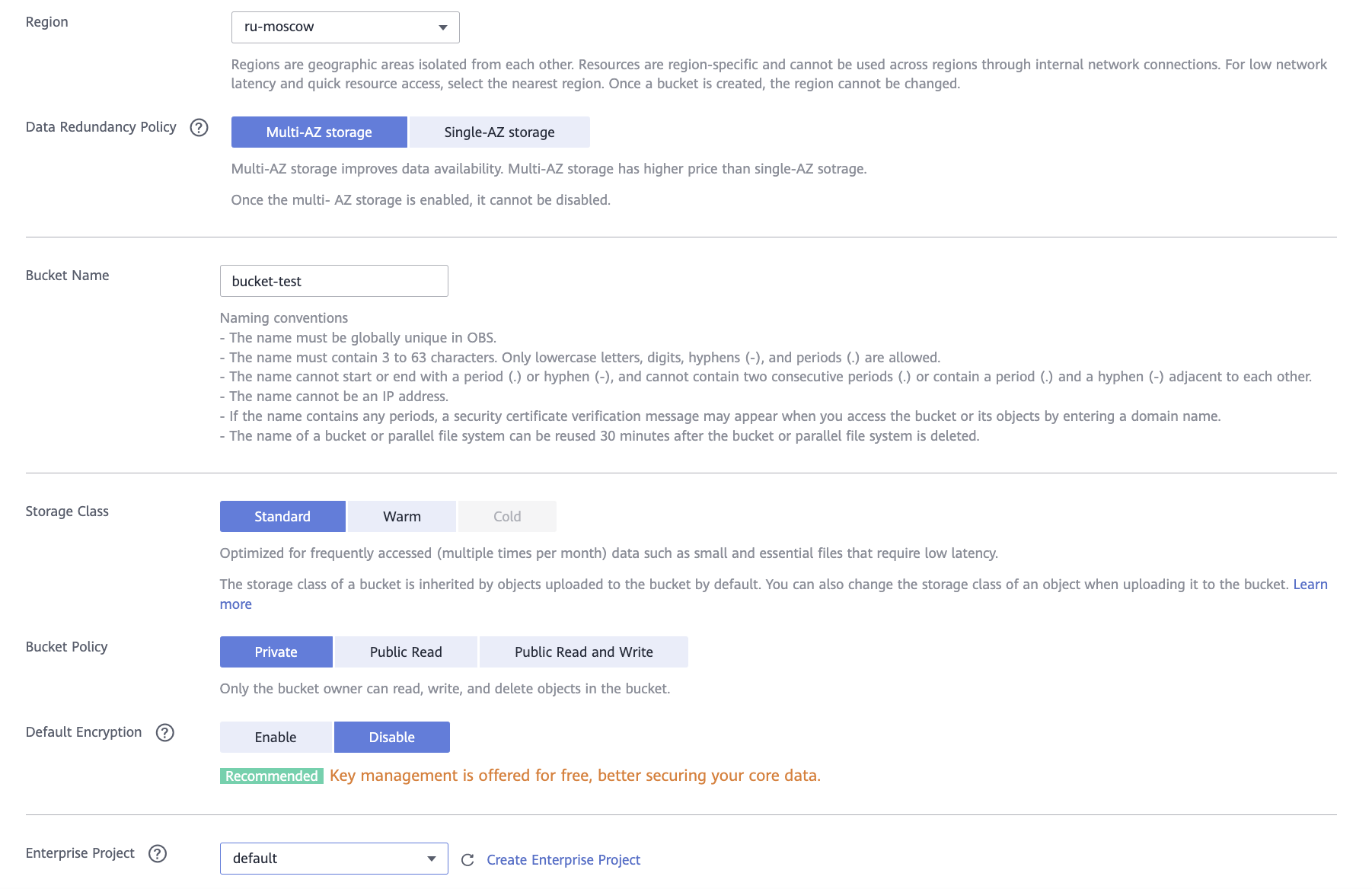
Чтобы завершить создание бакета, нажмите Create Now.
После создания бакет появится в списке.
Чтобы загрузить в бакет исходные данные:
Нажмите на созданный бакет и в левом меню выберите Objects.
Нажмите Upload Object.
Чтобы загрузить два CSV-файла с данными, в диалоговом окне нажмите Add File.
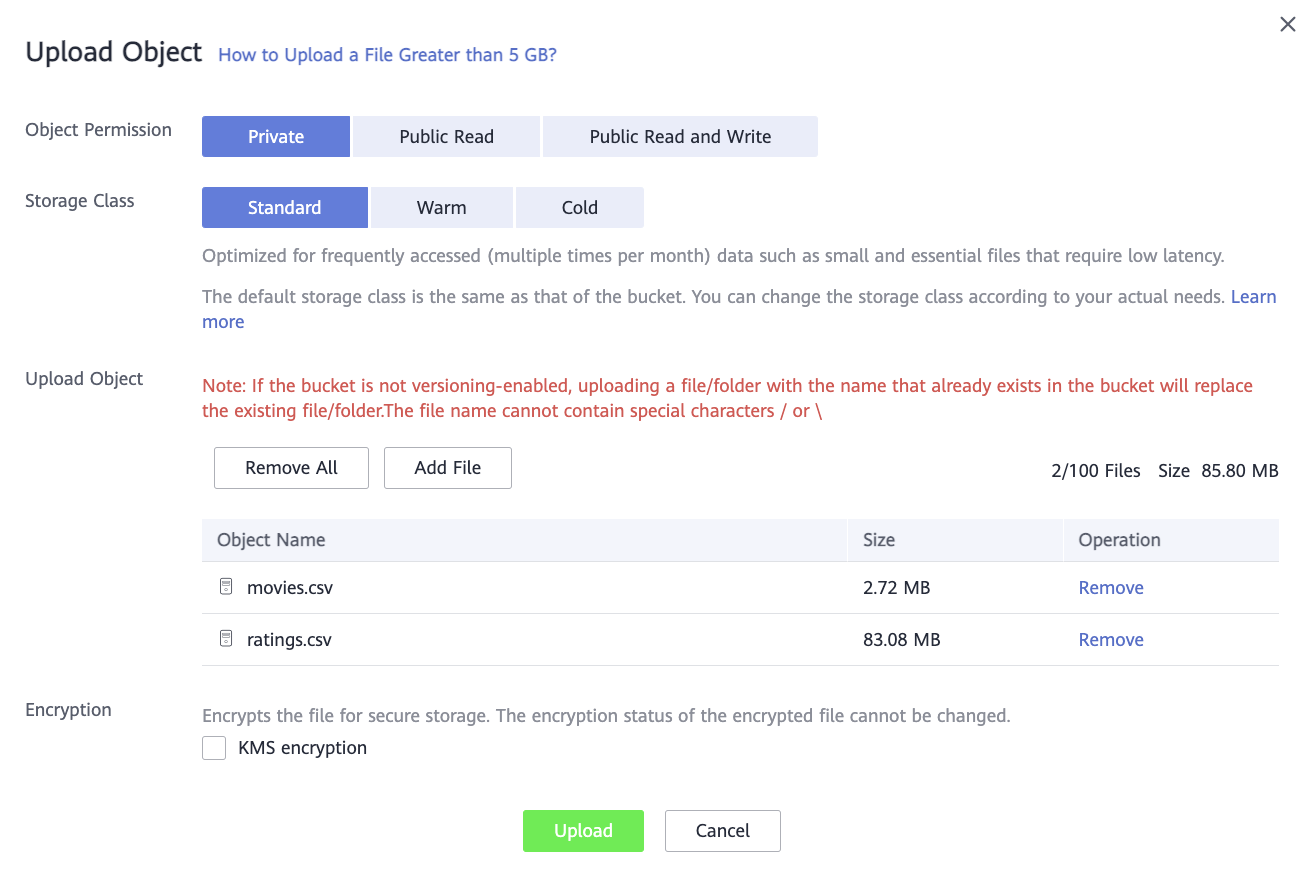
Нажмите Upload и дождитесь окончания загрузки файлов.
Теперь сервисы подготовлены и можно переходить к решению задачи.
Решение задачи в MRS с помощью Spark Submit
Для решения задачи можно написать код на Python, который прочитает данные по указанному пути, соберет данные и запишет в выходной каталог.
Создайте файл spark-mrs-1.py и добавьте в него следующий код:
from pyspark.sql import SparkSessionfrom pyspark.sql import functions as fimport sysmovies_path = sys.argv[1]ratings_path = sys.argv[2]save_path = sys.argv[3]spark = SparkSession.builder.appName('Movie_Rating_Above_4').getOrCreate()df_movies = spark.read.csv(movies_path, header=True, inferSchema=True)df_ratings = spark.read.csv(ratings_path, header=True, inferSchema=True)df_movie_rating = df_movies.join(df_ratings, "movieId", "left")df_calculated = df_movie_rating.groupBy("title").agg(f.avg("rating").alias("avg_rating"))df_calculated_above_four = df_calculated.filter("avg_rating > 4").select(["title","avg_rating"])df_calculated_above_four.write.csv(save_path, header=True)- Этот код:
Принимает несколько аргументов:
путь к файлу с фильмами;
путь к файлу с рейтингами;
путь до папки, в которой необходимо сохранить результат.
Считывает данные из файлов с фильмами и рейтингами.
Объединяет данные в один массив по идентификатору фильма.
Агрегирует данные по фильмам и считает средний рейтинг (рейтинг добавляется как столбец avg_rating).
Фильтрует полученный массив данных.
Сохраняет данные в формате csv в папку.
Для запуска задания в сервисе MRS необходимо также загрузить файл spark-mrs-1.py в бакет OBS, в который были загружены файлы с данными. Чтобы загрузить:
Войдите в консоль управления Advanced:
В списке сервисов выберите Object Storage Service.
Нажмите на созданный бакет и в левом меню выберите Objects.
Нажмите Upload Object.
Чтобы загрузить spark-mrs-1.py с кодом, в диалоговом окне нажмите Add File.
Нажмите Upload и дождитесь окончания загрузки файла.
После того, как файл был загружен, запустите задание в сервисе MRS. Для этого:
Войдите в консоль управления Advanced:
В списке сервисов выберите MapReduce Service.
В списке нажмите на название ранее созданного кластера.
Перейдите на вкладку Jobs и нажмите Create.
Задайте параметры:
Type — SparkSubmit.
Name — название задания.
Program Path — нажав кнопку OBS, выберите бакет, а затем загруженный ранее в него файл spark-mrs-1.py. Активируйте опцию «I confirm that the selected script is secure, and I understand the potential risks and accept the possible exceptions or impacts on the cluster» и нажмите OK.
Parameters — через пробел укажите путь до файлов movies.csv, ratings.csv, а также путь до папки, куда необходимо сохранить результат (папки не должно существовать).
Пример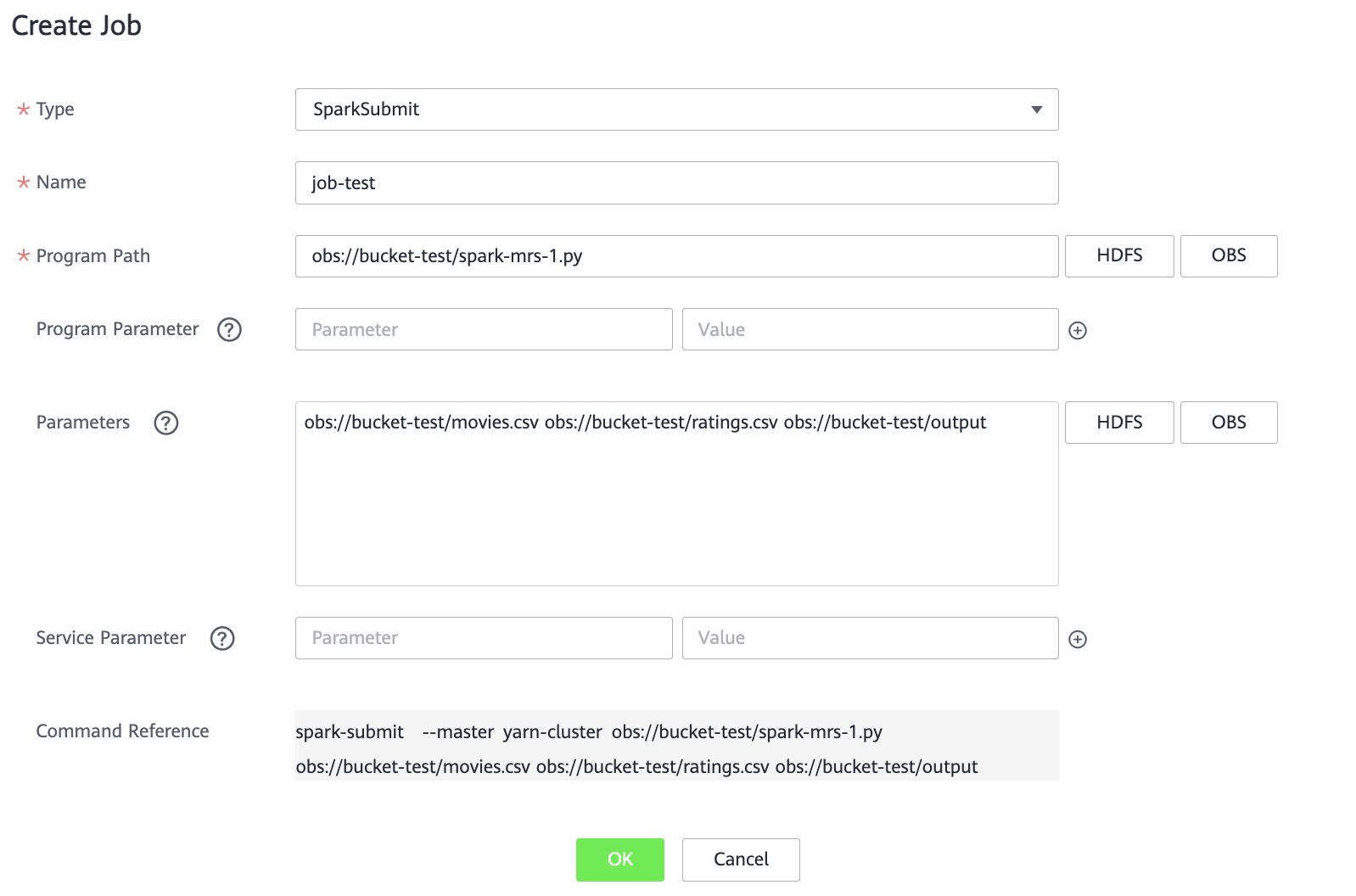
Нажмите OK.
Задание отображается в списке со статусом «Submitted». Подождите несколько минут и обновите страницу. Статус задания изменится на «Completed», а результат — на «Successful».
Чтобы проверить результат выполнения:
Откройте бакет OBS, путь до которого был указан в процессе создания задания.
В бакете появилась папка для сохранения результатов.
Нажмите на название папки.
В ней содержится файл _SUCCESS, а также набор CSV-файлов с результатами.
Скачайте любой из файлов и проверьте, что результат соответствует условиям задачи.
Решение задачи в MRS с помощью Spark SQL
Теперь попробуйте решить ту же самую задачу с использованием языка SQL и без написания кода на Python. Необходим следующий SQL-запрос (измените название бакета на ваше):
CREATE TEMPORARY VIEW movies (movieId int,title string,genres string)USING csvOPTIONS (path 'obs://bucket-test/movies.csv',header true);CREATE TEMPORARY VIEW ratings (userId int,movieId int,rating float,timestamp string)USING csvOPTIONS (path 'obs://bucket-test/ratings.csv',header true);INSERT OVERWRITE DIRECTORY 'obs://bucket-test/output' USING CSVSELECT movies.title, AVG(ratings.rating) as avg_ratingFROM movies LEFT JOIN ratings ON movies.movieId = ratings.movieIdGROUP BY movies.titleHAVING avg_rating > 4
Этот скрипт выполняет то же самое, что и скрипт Python в предыдущем задании:
Подключается к файлам в OBS.
Агрегирует данные.
Сохраняет результат в каталог на OBS.
Чтобы запустить задание:
Войдите в консоль управления Advanced:
В списке сервисов выберите MapReduce Service.
В списке нажмите на название ранее созданного кластера.
Перейдите на вкладку Jobs и нажмите Create.
Задайте параметры:
Type — SparkSql.
Name — название задания.
SQL Type — Script. Введите скрипт SQL, указанный ранее.
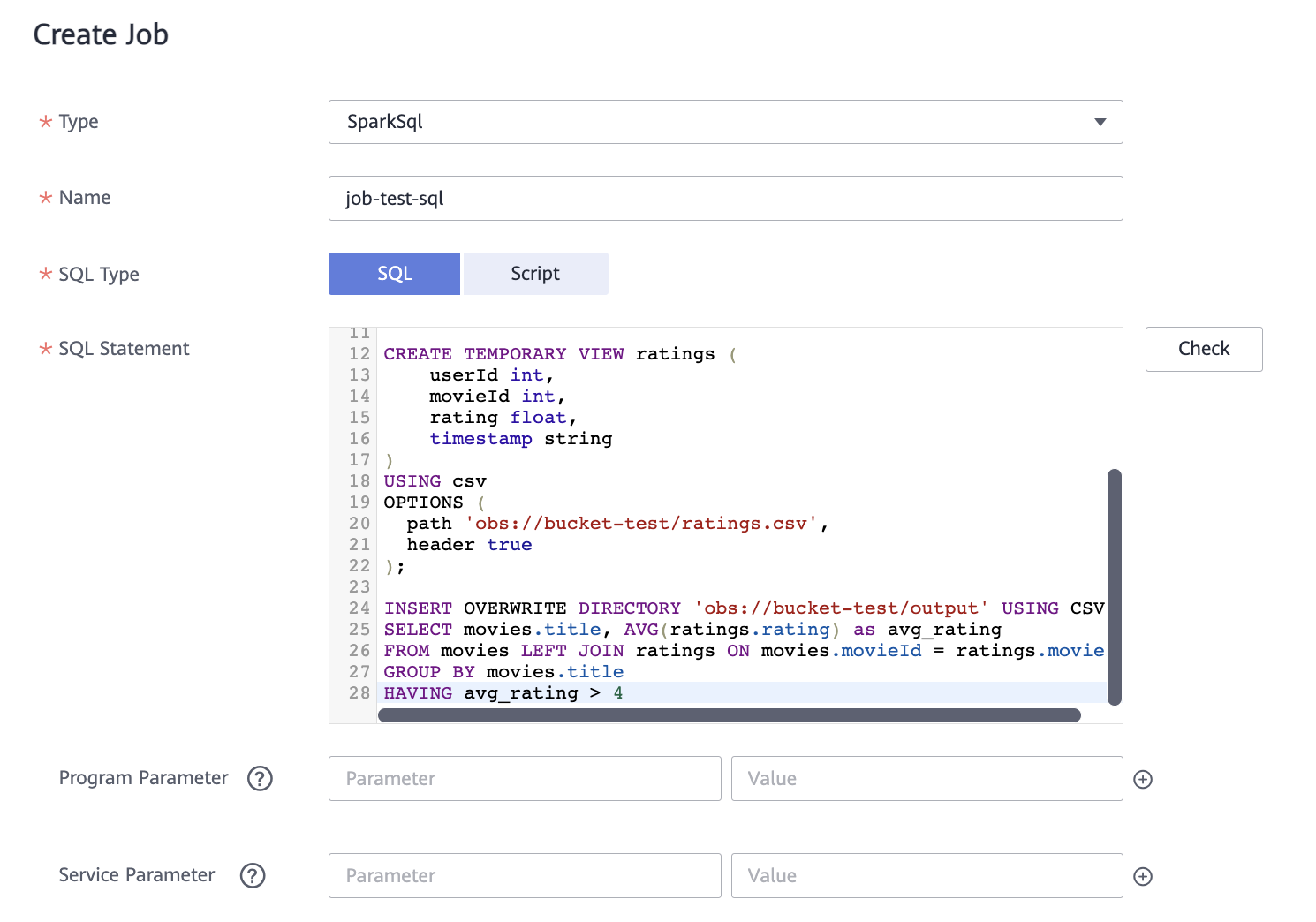
Нажмите OK.
Задание отображается в списке со статусом «Running». Подождите несколько минут и обновите страницу. Статус задания изменится на «Completed», а результат на «Successful».
Чтобы проверить результат выполнения:
Откройте бакет OBS, путь до которого был указан в процессе создания задания.
В бакете появилась папка для сохранения результатов.
Нажмите на название папки.
В ней содержится файл _SUCCESS, а также набор CSV-файлов с результатами.
Скачайте любой из файлов и проверьте, что результат соответствует условиям задачи.
Решение задачи в DLI с помощью Spark Submit
Теперь можно обработать те же самые данные с помощью сервиса DLI. То есть вы не создаете кластер, не просматриваете виртуальные машины и не отслеживаете их состояние. Единственное, что доступно для настройки — параметры очереди, в которой будет выполняться задание.
Запустите ваш скрипт на Python в DLI (Для получения и сохранения данных также будет использоваться OBS):
Войдите в консоль управления Advanced:
В списке сервисов выберите Data Lake Insight.
Выберите Job Management → Spark Jobs.
В правом верхнему углу нажмите Create Job.
На вкладке Fill Form задайте параметры:
Queue — очередь, которая была создана в начале работы для типа задания Spark Submit.
Job Name — название задания.
Application — с помощью кнопки справа выберите созданный бакет OBS, а затем файл spark-mrs-1.py.
Application Parameters — на отдельных строках укажите путь до файла movies.csv, ratings.csv, а также путь до папки, куда необходимо сохранить результат (папки не должно существовать).
Пример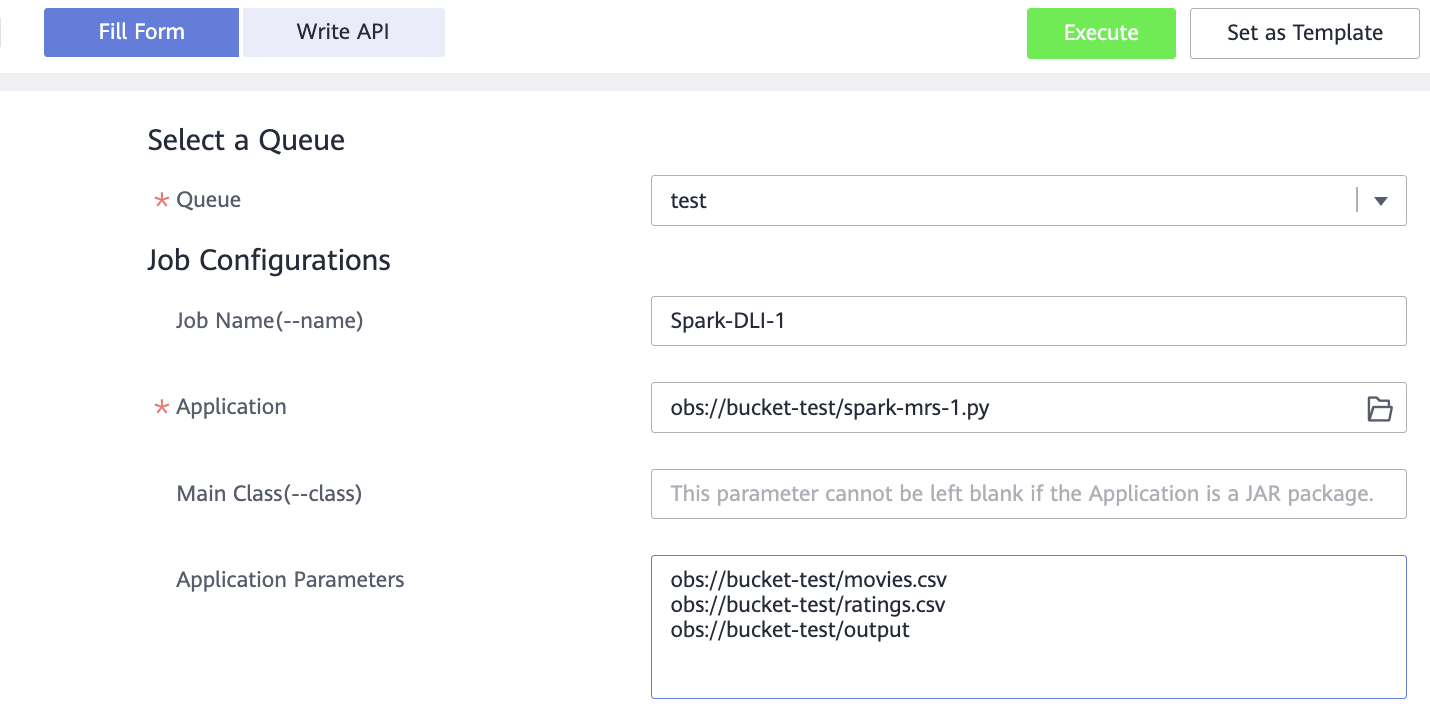
В правом верхнем углу нажмите Execute.
На странице Spark Jobs в списке появится созданное задание со статусом «Starting». Подождите несколько минут и обновите страницу. Статус запроса изменится на «Finished».
Чтобы проверить результат выполнения:
Откройте бакет OBS, путь до которого был указан в процессе создания задания.
В бакете появилась папка для сохранения результатов.
Нажмите на название папки.
В ней содержится файл _SUCCESS, а также набор CSV-файлов с результатами.
Скачайте любой из файлов и проверьте, что результат соответствует условиям задачи.
Решение задачи в DLI с помощью Spark SQL
Теперь выполните анализ данных с помощью Spark SQL, который представлен в виде пользовательского интерфейса в DLI. Нужно будет создать мета-базу данных и мета-таблицы для работы. Они не будут содержать в себе данные, но будут ссылаться на данные в наших CSV-файлах, хранящихся в OBS. После этого вы сможете написать SQL-запрос для анализа данных из этих мета-таблиц.
Войдите в консоль управления Advanced:
В списке сервисов выберите Data Lake Insight.
В меню слева выберите SQL Editor.
Нажмите
 на вкладке Databases.
на вкладке Databases.
В диалоговом окне задайте параметры:
Database Name — название базы данных.
Enterprise Project — выберите необходимый проект или default.
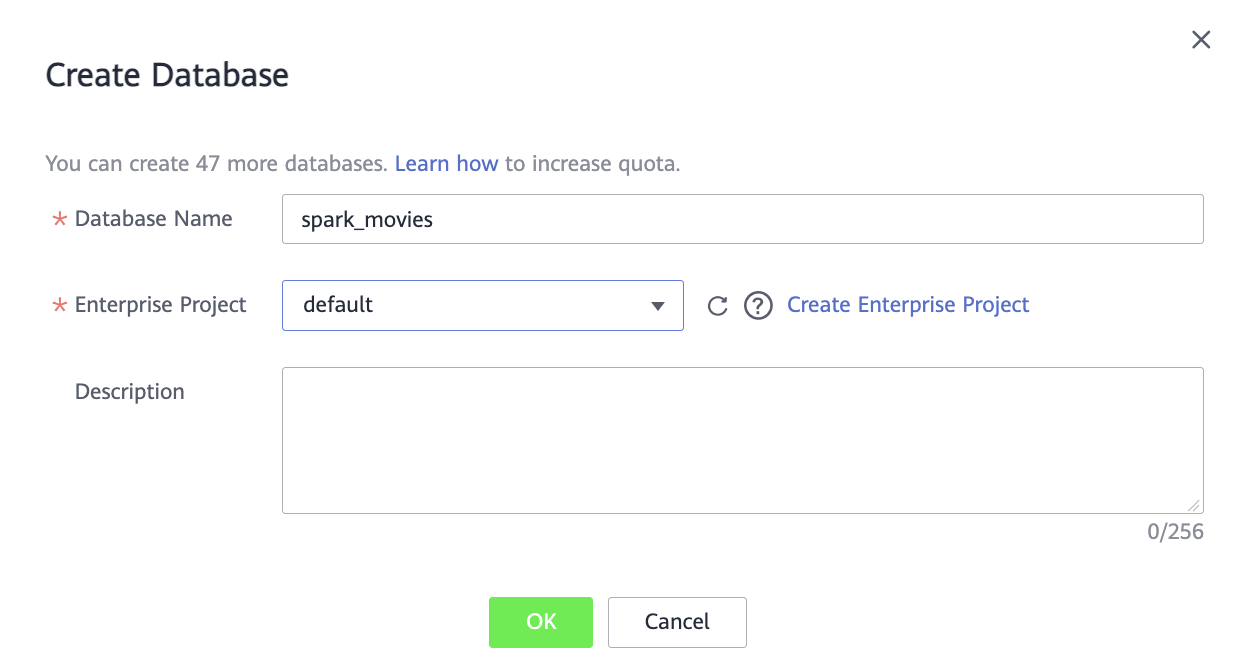
Чтобы завершить создание базы данных, нажмите OK.
Нажмите на созданную базу данных. Откроется поле Table.
Нажмите на
и задайте параметры таблицы movies:Name — название таблицы.
Data Location — OBS.
Data Format — CSV.
Bucket Location — с помощью кнопки справа выберите созданный бакет OBS, а затем файл movies.csv.
Опишите столбцы по примеру ниже. Добавлять столбцы можно кнопкой
в правой части таблицы.Column Name (Название столбца)
Type (Тип данных)
movieId
int
title
string
genres
string
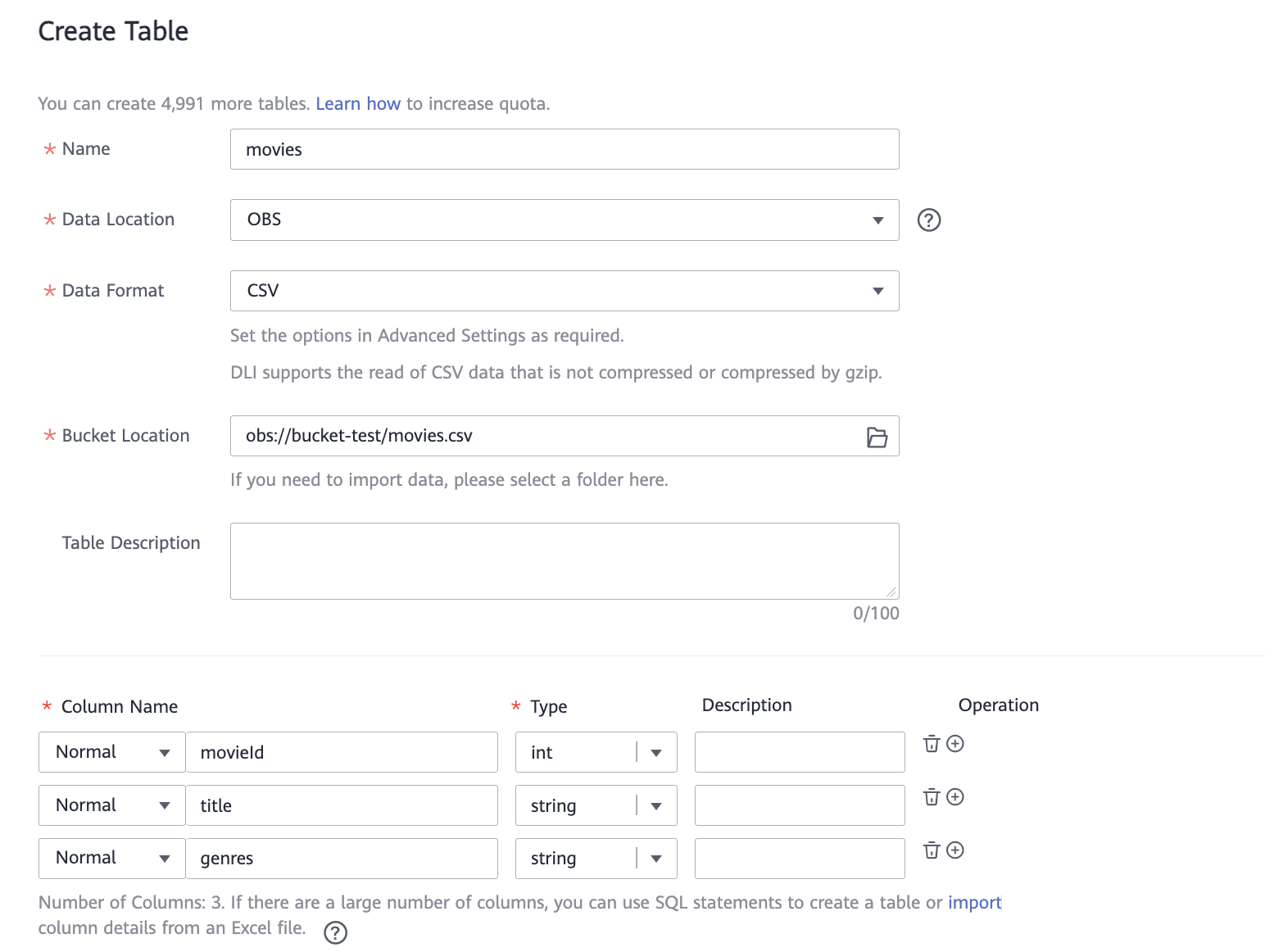
Включите опцию Advanced settings и активируйте Table Header.
Нажмите OK.
По аналогии создайте таблицу ratings со столбцами:
Column Name (Название столбца)
Type (Тип данных)
userId
int
movieId
int
rating
double
timestamp
string
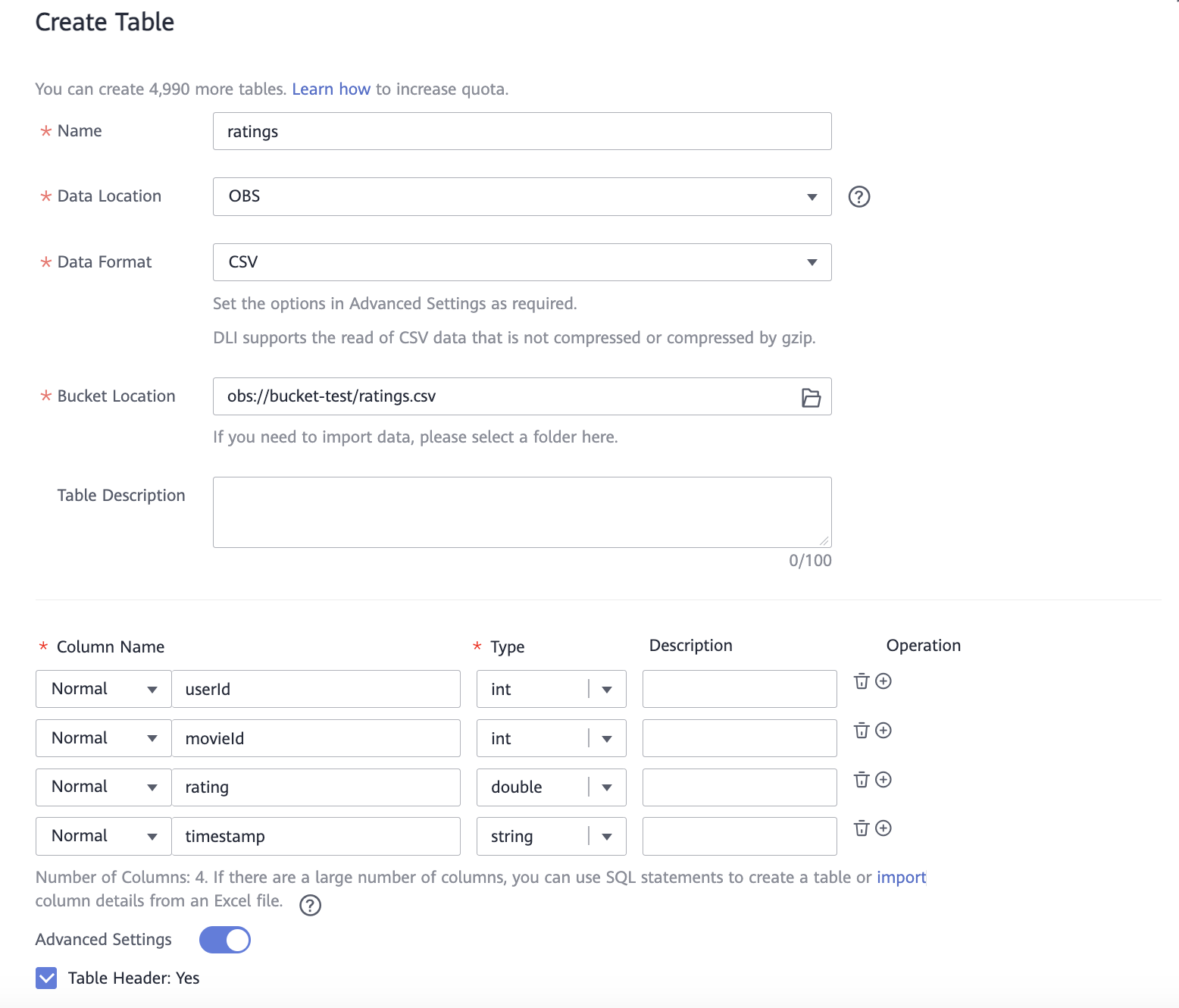
Нажмите OK.
После того, как таблицы описаны, в правой части можно выполнить SQL запрос. Для этого вставьте запрос ниже в поле:
INSERT OVERWRITE DIRECTORY 'obs://bucket-test/output'USING csvSELECT movies.title, AVG(ratings.rating) as avg_ratingFROM movies LEFT JOIN ratings ON movies.movieId = ratings.movieIdGROUP BY movies.titleHAVING avg_rating > 4В верхней части поля нажмите Execute.
Статус выполнения запроса отобразится в нижней части экрана на вкладке Executed Queries.
Чтобы просмотреть статус выполнения задачи, в меню слева выберите Job Management → SQL Jobs. Успешная операция подтверждается статусом «Finished».
(Опционально) Сборка файлов в один с помощью FunctionGraph
Для сборки этих файлов в один можно использовать функцию FunctionGraph, которая будет запускаться при создании файла в заданном ранее каталоге объектного хранилища с именем _SUCCESS.
Код функции:
# -*- coding: utf-8 -*-from com.obs.client.obs_client import ObsClientimport ioimport datetimedef handler(event, context):date = datetime.datetime.now()AK = context.getAccessKey()SK = context.getSecretKey()server = 'obs.ru-moscow-1.hc.sbercloud.ru'bucketName = 'bucket-test'obsClient = ObsClient(access_key_id=AK, secret_access_key=SK, server=server)csv_mem = io.StringIO()list_objects = obsClient.listObjects(bucketName, prefix='output')for content in list_objects.body.contents:if (content.key.find('.csv') != -1):objectKey = str(content.key)resp = obsClient.getObject(bucketName, objectKey, loadStreamInMemory=True)if resp.body != None:download_object = resp.body.buffercsvdata = download_object.decode("utf-8")csv_mem.write(csvdata)objectKey = f"output_{date}.csv"obsClient.putContent(bucketName, objectKey, csv_mem.getvalue())return "OK"