В больших компаниях при формировании отчетности или для обеспечения работы аналитиков принято строить корпоративные хранилища данных. Они способны обрабатывать большие объемы информации и делать это быстрее классических СУБД.
Для хранения такой информации принято использовать базы данных типа Massive Parallel Processing. Они позволяют быстрее выполнять аналитические запросы за счет:
возможности разделить информацию из таблиц для хранения на нескольких серверах;
возможности проанализировать входящий SQL-запрос и запустить его параллельно на нескольких серверах для обработки части информации;
возможности собрать результаты выполнения параллельных запросов и вернуть клиенту результирующий набор данных.
В облаке Advanced можно создать MPP-корпоративное хранилище данных на движке GaussDB, основанном на PostgreSQL, с помощью Data Warehouse Service (DWS). Сервис DWS:
Обладает хорошей отказоустойчивостью. Вместо единого мастера в сервисе используется несколько «coordinator node».
Обладает хорошими возможностями масштабирования.
Поддерживает миллиардные БД.
Поддерживает разные варианты хранения таблиц и методы дистрибуции данных между узлами.
При работе с большинством MPP нужно уделять особое внимание тому, как данные будут храниться и распределяться между серверами. Это напрямую влияет на производительность запросов.
Сценарий
В рамках практической работы будет проведено несколько экспериментов с разными вариантами хранения данных на инстансах DWS. Будут выполняться запросы к базе данных, которая содержит информацию о фильмах и их оценках от пользователей.
База данных состоит из таблиц:
movieId | title | genres |
|---|---|---|
1 | Дьявол носит Prada (2006) | Комедия, драма |
2 | Однажды в… Голливуде (2019) | Комедия, драма |
3 | Шрек (2001) | Комедия, фэнтези |
userId | movieId | rating | timestamp |
|---|---|---|---|
1 | 2 | 4.0 | 2018-03-27 00:51:45 |
2 | 4 | 3.0 | 2018-03-26 23:37:22 |
Задача состоит в том, чтобы получить список фильмов с их средней оценкой.
Перед началом работы
В практической работе будут протестированы некоторые возможности специализированных MPP-инструментов, которые используются для оптимизации выполнения запросов.
Разделение данных
При создании таблиц можно задать параметр DISTRIBUTE BY. Он указывает СУБД на то, каким образом нужно разделить данные между разными серверами кластера.
По умолчанию данные разделяются последовательно:
первая запись хранится на первом сервере;
вторая запись хранится на втором сервере;
третья запись хранится на третьем сервере;
четвертая запись хранится на первом сервере;
пятая запись хранится на втором сервере.
С точки зрения оптимизации запросов такой подход может быть не оптимальным, потому что для выполнения фильтраций сначала придется собирать информацию со всех серверов, а только потом фильтровать.
Если указать разделение на основе одного или нескольких полей, записи с одинаковыми значениями будут храниться на одном сервере. С одной стороны такой подход позволит оптимизировать фильтрации, потому что данные можно отфильтровать на одном сервере без необходимости их предварительного сбора. С другой стороны это может привести к перекосу в хранении, когда количество записей сильно отличается в зависимости от набора значений полей, которые указаны в DISTRIBUTE BY.
При проектировании БД рекомендуется оценить типовые SQL-запросы и применяемые фильтрации, чтобы при разделении данных выбрать правильные поля.
Хранение данных по строкам и столбцам
При создании таблиц можно указать параметр ORIENTATION. Он указывает на то, как данные должны храниться на диске конечного сервера кластера.
Если данные хранятся в строках, СУБД будет полностью считывать запись (строку) при выполнении запросов, а потом выбирать из нее нужные в запросе столбцы.
Если данные хранятся в колонках, СУБД может сразу считать только необходимые столбцы, что увеличит скорость выполнения запроса. Хранение в столбцах также позволяет оптимизировать место на дисках, которое занимают данные.
Если в вашей базе данных есть таблица фактов с множеством столбцов, но запросы используют только их малую часть, хранение в колоночном виде может заметно ускорить выполнение запроса.
Партиционирование данных
Упорядочивание данных по определенному параметру позволяет сгруппировать и хранить рядом записи, которые часто запрашиваются одновременно. Данные в партициях при этом не пересекаются, а движок СУБД при наличии фильтраций по этим полям сможет считывать конкретные партиции, игнорируя другие данные.
Чтобы использовать партиционирование данных в DWS, таблицы нужно создавать с параметром PARTITION BY.
Подготовка инструментов
Чтобы упростить выполнение практической работы, подключаться к сервису DWS можно через публичный IP-адрес с помощью pgAdmin.
Для подготовки практической работы:
Скачайте и установите pgAdmin.
ПримечаниеПри использовании pgAdmin 4 v7.3 на Windows 10 может возникнуть проблема, при которой вместо вывода данных из БД, выводится ошибка string indices must be integers. Если вы столкнулись с этой проблемой, попробуйте воспользоваться более ранней версией pgAdmin, например v6.21.
Узнайте свой внешний IP-адрес. Например, с помощью сервиса https://www.myip.ru.
Подготовка данных
В практической работе будут использоваться данные из публичного датасета. Его можно скачать по ссылке.
Для работы понадобятся два файла:
movies.csv
ratings.csv
Подготовка инфраструктуры
Для выполнения практической работы понадобятся два сервиса облака Advanced:
Object Storage Service (OBS), в который будут загружены файлы с данными.
Data Warehouse Service (DWS), в котором данные будут храниться и обрабатываться.
Создание бакета OBS
Исходные данные нужно импортировать в DWS. Для этого сначала их нужно поместить в хранилище, доступное используемым в практической работе сервисам. В Advanced есть сервис хранения и управления объектным хранилищем данных — Object Storage Service (OBS).
Чтобы создать OBS-бакет:
Войдите в консоль управления Advanced:
В списке сервисов выберите Object Storage Service.
В правом верхнем углу нажмите Create Bucket.
Data Redundancy Policy — для практической работы не требуется мультизональное хранилище (Multi-AZ storage), поэтому выберите Single-AZ storage.
Bucket Name — задайте название бакета.
Storage Class — выберите класс хранения Standard.
Bucket Policy — выберите Private.
ПримечаниеPrivate — только владелец может смотреть, изменять и удалять объекты бакета.
Public Read — любой пользователь может просматривать содержимое бакета. Только владелец имеет право изменять и удалять объекты бакета.
Public Read and Write — любой пользователь может смотреть, изменять и удалять объекты бакета.
Default Encryption — выберите Disable. Для выполнения практической работы шифрование объектов в бакете не требуется.
Enterprise Project — выберите Enterprise-проект, в котором будет создан бакет.
Нажмите Create Now.
После создания бакет появится в общем списке.
Загрузка исходных данных в бакет
Чтобы загрузить CSV-файлы с исходными данными в бакет:
Нажмите на название созданного бакета.
В левом меню перейдите в раздел Objects.
Нажмите Upload Object.
Перетащите файлы movies.csv и ratings.csv в окно загрузки или нажмите add file и выберите их в проводнике.
Нажмите Upload.
Дождитесь окончания загрузки файлов. Когда файлы будут загружены, они появятся в списке.
Создание виртуальной сети
Для работы DWS нужно создать виртуальную сеть, в которую будут добавлены сервера кластера. Чтобы создать сеть:
В левом верхнем углу консоли управления нажмите Homepage.
В списке сервисов выберите Virtual Private Cloud.
В правом верхнем углу нажмите Create VPC.
В поле Name задайте название виртуальной сети.
IPv4 CIDR Block — адресное пространство сети. Укажите 192.168.0.0/24.
Enterprise Project — выберите тот же Enterprise-проект, в котором находится ранее созданный бакет.
В поле Name в разделе Default Subnet задайте название подсети.
Нажмите Create Now.
Виртуальная сеть создана.
Создание группы безопасности
Для подключения к кластеру DWS с публичного IP-адреса нужно создать и настроить группу безопасности — межсетевой экран уровня ресурса в облаке. Для этого:
В консоли управления на странице Virtual Private Cloud в левом меню перейдите в раздел Access Control → Security Groups.
В правом верхнем углу нажмите Create Security Group.
В поле Name задайте название группы безопасности.
Enterprise Project — выберите тот же Enterprise-проект, в котором ранее создали бакет и виртуальную сеть.
Template — выберите Custom.
Нажмите OK.
Нажмите Manage Rule.
Переключитесь на вкладку Inbound Rules.
Нажмите Add Rule.
Заполните параметры для правила:
Priority — 1
Action — Allow
Protocol & Port — TCP, 8000
Type — IPv4
Source — IP address, ваш внешний IP-адрес с подсетью 32 (например 203.0.113.1/32)
Нажмите OK.
Группа безопасности создана и настроена.
Создание кластера DWS
Чтобы создать кластер Data Warehouse Service:
В левом верхнем углу консоли управления нажмите Homepage.
Выберите сервис Data Warehouse Service.
В правом верхнем углу нажмите Create Service.
AZ — выберите любую зону доступности, в которой будет размещен кластер.
Node Flavor — выберите минимальную конфигурацию узла. Для выполнения практической работы будет достаточно флейвора «dwsx2.xlarge.m7n».
Hot storage — выберите минимально допустимый объем хранилища — 20 ГБ.
nodes — выберите минимально допустимое количество узлов — 3.
В поле Cluster Name задайте название кластера DWS.
В поле Administrator Account задайте имя пользователя для подключения к кластеру.
В поле Administrator Password задайте пароль пользователя.
В поле Confirm Password введите пароль повторно.
В поле Database Port укажите порт для подключения к кластеру — 8000.
VPC — выберите созданную ранее виртуальную сеть.
Subnet — выберите созданную ранее подсеть.
Security Group — выберите созданную ранее группу безопасности.
EIP — чтобы автоматически назначить кластеру публичный IP-адрес, выберите Automatically Assign.
См.такжеЧтобы подтвердить автоматическое создание агентства, нажмите Yes. Агентства используются для доступа одних облачных сервисов облака Advanced к другим.
Bandwidth — выберите пропускную способность в 10 Мбит/с.
Enterprise Project — выберите тот же Enterprise-проект, в котором ранее создали бакет, виртуальную сеть и группу безопасности.
Advanced Settings — выберите Default.
Нажмите Create Now.
Чтобы подтвердить создание кластера DWS, нажмите Submit.
Нажмите Back to Cluster List.
Когда кластер будет создан, его статус сменится с «Creating» на «Available».
Создание Access Keys
Для подключения к OBS из DWS нужно создать ключи для доступа по API. Для этого:
В правом верхнем углу консоли управления Advanced нажмите на имя пользователя и выберите My Credentials.
В меню слева перейдите в раздел Access Keys.
Нажмите Create Access Keys.
При необходимости введите описание ключа в поле Description и нажмите OK.
Чтобы скачать файл с ключами, нажмите Download. Ключи можно скачать только один раз после их создания.
Подключение к кластеру с помощью pgAdmin
Для упрощения работы с кластером и тестирования запросов воспользуйтесь pgAdmin:
В левом верхнем углу консоли управления нажмите Homepage.
В списке сервисов выберите Data Warehouse Service.
Нажмите на название созданного кластера.
В меню справа в поле Public Network IP Address скопируйте публичный IP-адрес кластера.
Запустите клиент pgAdmin.
Нажмите Add New Server.
В поле Name задайте название сервера.
Переключитесь на вкладку Connection.
В поле Host name/address вставьте публичный IP-адрес кластера, который скопировали ранее.
В поле Port введите 8000.
В поле Username введите имя пользователя, которое указывали при создании кластера DWS.
В поле Password введите пароль пользователя, который задавали при создании кластера DWS.
Чтобы не вводить пароль при каждом подключении, активируйте параметр Save password.
Нажмите Save.
При сохранении данных клиент попытается подключиться к кластеру. В ходе подключения может возникнуть ошибка:
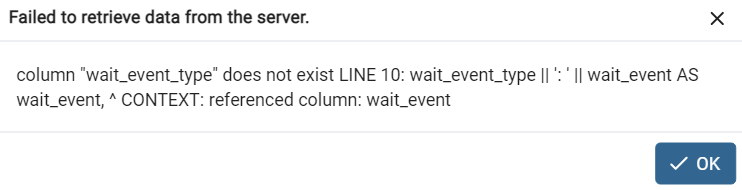
При возникновении ошибки нажмите OK.
Инфраструктура готова к выполнению практической работы с данными. Теперь можно перейти к созданию отдельной базы данных, в которой будет проводиться тестирование итоговых запросов и конфигурации.
Создание базы данных
Чтобы создать базу данных:
В меню слева выберите Databases → postgres.
Нажмите
 (Query Tool).
(Query Tool).Введите SQL-запрос для создания базы данных:
CREATE DATABASE moviesЧтобы выполнить запрос, нажмите
 (Execute).
(Execute).
База данных создана. Чтобы перейти к выполнению запросов в ней:
В левом меню нажмите правой кнопкой мыши на Databases.
Нажмите Refresh.
Выберите базу данных «movies» и нажмите
(Query Tool).
База данных «movies» готова к выполнению запросов.
Создание внешних таблиц
При выполнении практической работы будет выполнено несколько экспериментов, в рамках которых нужно будет копировать данные. Чтобы упростить процесс копирования, нужно создать внешние таблицы, которые будут указывать на файлы в объектном хранилище OBS. Данные будут копироваться из внешних таблиц.
Таблицы будут храниться в отдельной схеме. Чтобы создать схему, выполните запрос:
CREATE SCHEMA obs AUTHORIZATION dbadmin;CREATE FOREIGN TABLE obs.movies(movieId INTEGER,title VARCHAR(255) NOT NULL,genres VARCHAR(500) NOT NULL)SERVER gsmpp_serverOPTIONS(LOCATION 'obs://bucket-test/movies.csv',FORMAT 'CSV' ,DELIMITER ',',encoding 'utf8',header 'true',ACCESS_KEY 'Ключ Access Key',SECRET_ACCESS_KEY 'Ключ Secret Key')READ ONLY;CREATE FOREIGN TABLE obs.ratings(userId INTEGER,movieId INTEGER,rating DOUBLE PRECISION,timestamp varchar(100))SERVER gsmpp_serverOPTIONS(LOCATION 'obs://bucket-test/ratings.csv',FORMAT 'CSV' ,DELIMITER ',',encoding 'utf8',header 'true',ACCESS_KEY 'Ключ Access Key',SECRET_ACCESS_KEY 'Ключ Secret Key')READ ONLY;
В коде запроса замените:
dbadmin на имя пользователя, которое указали при создании кластера DWS;
bucket-test на название бакета, которое вы указали при его создании;
Ключ Access Key на Access Key из файла credentials.csv;
Ключ Secret Key на Secret Key из файла credentials.csv.
Этот SQL-запрос создаст таблицы в схеме obs. Таблицы будут ссылаться на внешнее хранилище. Чтобы проверить доступ, выполните запрос:
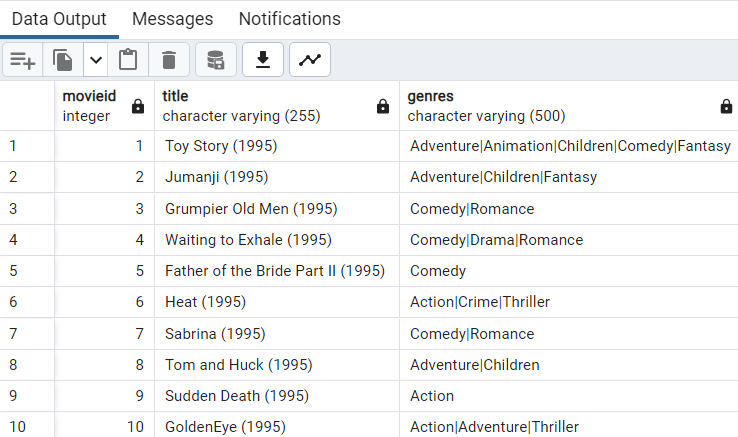
SELECT * FROM obs.movies LIMIT 10
В выводе появятся реальные данные, которые находятся в файлах:
Первоначальная схема хранения
На этом этапе будут созданы первые таблицы, в которые будут скопированы данные. На этих таблицах будут проверены SQL-запросы.
В таблицах специально не будет отмечен Primary key. Зачастую первичные ключи игнорируют при обработке больших объемов данных, чтобы избежать ошибок при импорте. Отказ от Primary key также позволит проэмулировать разделение данных между серверами по очереди.
Данные будут храниться в виде строк.
Чтобы создать отдельную схему и таблицы для хранения информации:
Выполните запрос:
CREATE SCHEMA test1 AUTHORIZATION dbadmin;CREATE TABLE test1.movies (movieId INTEGER,title VARCHAR(255) NOT NULL,genres VARCHAR(500) NOT NULL) WITH (ORIENTATION = ROW)DISTRIBUTE BY ROUNDROBIN;CREATE TABLE test1.ratings (userId INTEGER,movieId INTEGER,rating double precision,timestamp varchar(100)) WITH (ORIENTATION = ROW)DISTRIBUTE BY ROUNDROBIN;Скопируйте данные из внешних таблиц в созданные таблицы:
INSERT INTO test1.movies SELECT * FROM obs.movies;INSERT INTO test1.ratings SELECT * FROM obs.ratings;Проверьте, что из созданных таблиц можно получить данные:
SELECT * FROM test1.movies LIMIT 10Цель — измерить время выполнения запроса рейтинга фильмов. Для этого нужно выполнить запрос несколько раз. В pgAdmin время исполнения запроса указывается под результатом выполнения в строке состояния. Чтобы получить рейтинг фильмов, выполните запрос:
select m.title, avg(r.rating) from test1.movies as m left join test1.ratings as r on m.movieId = r.movieId group by m.title
При разработке практической работы среднее время выполнения запроса рейтинга фильмов составило 4,8 с.
Также проверьте занятый объем дискового пространства:
В левом верхнем углу консоли управления нажмите Homepage.
В списке сервисов выберите Data Warehouse Service.
Нажмите на название созданного кластера.
В меню слева выберите Workload.
Раскройте список Schema Space Manage и нажмите на базу данных movies:
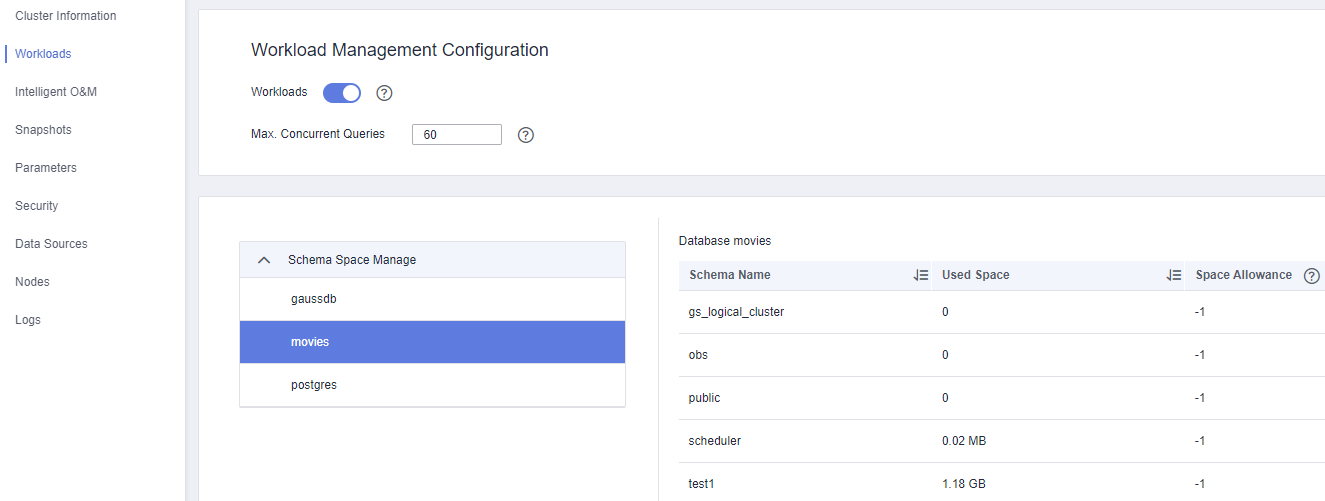
В таблице справа появятся схемы и их характеристики. Обратите внимание на два столбца — «Used Space» и «Skew Percent». На данный момент «Skew Percent» равен нулю, так как при создании таблиц использовалась конструкция DISTRIBUTE BY ROUNDROBIN. Благодаря ей данные равномерно распределились между всеми нодами.
Оптимизация схемы хранения для запросов
Для оптимизации запросов нужно понять, что происходит в движке СУБД при выполнении запроса.
Для анализа выполните запрос:
explain select m.title, avg(r.rating) from test1.movies as m left join test1.ratings as r on m.movieId = r.movieId group by m.title;
План выполнения, полученный при разработке практической работы:
id | operation | E-rows | E-memory | E-width | E-costs |
|---|---|---|---|---|---|
1 | -> Streaming (type: GATHER) | 6103 | 68 | 879540.40 | |
2 | -> HashAggregate | 6103 | 16MB | 68 | 879286.15 |
3 | -> Streaming(type: REDISTRIBUTE) | 18309 | 2MB | 68 | 879230.21 |
4 | -> HashAggregate | 18309 | 16MB | 68 | 878905.51 |
5 | -> Hash Right Join (6, 8) | 19993591 | 1MB | 36 | 845506.57 |
6 | -> Streaming(type: REDISTRIBUTE) | 19993591 | 2MB | 12 | 743731.57 |
7 | -> Seq Scan on ratings r | 19993591 | 1MB | 12 | 118133.30 |
8 | -> Hash | 27279 | 16MB | 32 | 931.10 |
9 | -> Streaming(type: REDISTRIBUTE) | 27278 | 2MB | 32 | 931.10 |
10 | -> Seq Scan on movies m | 27278 | 1MB | 32 | 180.93 |
Основные моменты:
Streaming(type: REDISTRIBUTE) — данные отправляются на все ноды кластера на основании указанных колонок;
Seq Scan — читает все записи в таблице;
Одна из «дорогих» операций — чтение данных из таблицы рейтингов на всех узлах.
Чтобы повысить производительность двух запросов, которые используются в практической работе, можно предположить, что:
наличие JOIN между таблицами может быть оптимальнее, если данные находятся на одном сервере;
используется всего два столбца в выводе.
Исходя из этих предположений, нужно создать новую схему данных, в которой:
параметр DISTRIBUTE BY ROUNDROBIN будет использовать поле «movieId», так как задача предполагает агрегацию данных по фильмам;
все таблицы будут храниться в колоночном виде.
Чтобы создать новую схему, таблицы и скопировать в них данные из внешних таблиц, выполните SQL-запрос:
CREATE SCHEMA test2 AUTHORIZATION dbadmin;CREATE TABLE test2.movies (movieId INTEGER PRIMARY KEY,title VARCHAR(255) NOT NULL,genres VARCHAR(500) NOT NULL) WITH (ORIENTATION = ROW)DISTRIBUTE BY HASH(movieId);CREATE TABLE test2.ratings (userId INTEGER,movieId INTEGER,rating double precision,timestamp varchar(100)) WITH (ORIENTATION = COLUMN)DISTRIBUTE BY HASH(movieId);INSERT INTO test2.movies SELECT * FROM obs.movies;INSERT INTO test2.ratings SELECT * FROM obs.ratings;
Когда запрос будет выполнен, проведите повторный тест производительности с помощью запроса:
select m.title, avg(r.rating) from test2.movies as m left join test2.ratings as r on m.movieId = r.movieId group by m.title
При разработке практической работы повторный подсчет среднего времени выполнения запроса составил 2,4 с.
Для анализа запроса выполните запрос:
explain select m.title, avg(r.rating) from test2.movies as m left join test2.ratings as r on m.movieId = r.movieId group by m.title
План выполнения, полученный при разработке практической работы:
id | operation | E-rows | E-memory | E-width | E-costs |
|---|---|---|---|---|---|
1 | -> HashAggregate | 2074 | 68 | 153484.16 | |
2 | -> Streaming (type: GATHER) | 6222 | 68 | 153484.16 | |
3 | -> HashAggregate | 6222 | 16MB | 68 | 153224.91 |
4 | -> Hash Right Join (5, 7) | 20000263 | 1MB | 36 | 119865.21 |
5 | -> Row Adapter | 20000262 | 1MB | 12 | 27903.75 |
6 | -> CStore Scan on ratings r | 20000263 | 1MB | 12 | 27903.75 |
7 | -> Hash | 27279 | 16MB | 32 | 179.93 |
8 | -> Seq Scan on movies m | 27278 | 1MB | 32 | 179.93 |
В таблице отсутствует «Streaming(type: REDISTRIBUTE)» и присутствует только один «Streaming (type: GATHER)». Это значит, что подсчет агрегатов выполняется в рамках одного узла и данные не перемещаются между серверами в кластере.
Чтобы оценить занимаемое место и разницу занимаемого объема данных на разных серверах, повторно проверьте таблицу Schema Space Manage.
В результате:
заметно снизилось занимаемое место на диске;
уменьшилось время выполнения запроса;
вырос показатель «Skew Percent», так как данные между узлами кластера распределились неравномерно — количество оценок у разных фильмов разное и у некоторых из них оценок больше.
За показателем «Skew Percent» нужно тщательно следить при проектировании и тестировании хранилища, так как при больших объемах данных его рост может негативно повлиять на производительность. Это связано с тем, что время работы запроса будет равно времени выполнения запроса на самом медленном узле. Если на одном из узлов кластера будет больше данных, чем на других, он будет обрабатывать запрос дольше всех.
Масштабируемый кластер
Так как MPP-системы обрабатывают данные параллельно на всех узлах, можно попробовать добавить новые серверы в кластер и измерить время выполнения запроса. Для этого:
В левом верхнем углу консоли управления нажмите Homepage.
В списке сервисов выберите Data Warehouse Service.
Нажмите на название кластера.
В правом верхнем углу нажмите Scale Out.
В поле Scale Out To укажите 6. Это значение, до которого будет увеличено количество узлов.
Advanced — выберите Custom.
Активируйте параметр Online Scale-out.
Redistribution Mode — выберите Online mode.
Нажмите Next: Confirm.
Нажмите Submit.
Когда масштабирование будет завершено, количество серверов в кластере будет увеличено, а данные между ними будут перераспределены.
Несколько раз проведите повторный тест производительности с помощью запроса:
select m.title, avg(r.rating) from test2.movies as m left join test2.ratings as r on m.movieId = r.movieId group by m.title
При разработке практической работы среднее время выполнения этого запроса составило 1,4 с.
Время выполнения запроса сократилось в два раза. Это логично, потому что теперь его параллельно обрабатывает в два раза большее количество серверов.
Денормализация данных
Часто при работе с аналитическими базами данных применяют денормализацию и хранят весь набор данных в виде одной плоской таблицы. Во многих случаях такой подход может повысить производительность ряда запросов.
Создайте отдельную схему и плоскую таблицу в ней с помощью запроса:
CREATE SCHEMA test3 AUTHORIZATION dbadmin;CREATE TABLE test3.ratings (movieId INTEGER,title VARCHAR(255) NOT NULL,genres VARCHAR(500) NOT NULL,userId INTEGER,rating double precision,timestamp varchar(100)) WITH (ORIENTATION = COLUMN)DISTRIBUTE BY HASH(movieId);INSERT INTO test3.ratings SELECT m.movieId, m.title, m.genres, r.userId, r.rating, r.timestamp FROM obs.movies m left join obs.ratings r on m.movieId = r.movieId;
Так как теперь таблица только одна, запрос среднего рейтинга фильмов видоизменился. Выполните новый вариант запроса несколько раз, чтобы измерить среднее время его исполнения:
select title, avg(rating) from test3.ratings group by title
При разработке практической работы среднее время выполнения этого запроса составило 0,6 с.
Для набора данных, который использовался в практической работе, и решения конкретно этой задачи, вариант с одной денормализованной таблицей оказался наиболее производительным.
В реальной жизни при проектировании хранилища данных также нужно понять, какие данные нужно будет хранить, как они могут храниться, какие запросы будут выполняться, а также протестировать несколько вариантов организации и хранения данных на объемах, приближенных к реальным.
Дополнительные возможности
В этом разделе будут рассмотрены возможности сервиса DWS, которые позволяют дополнительно оптимизировать обработку данных.
Использование холодного хранилища
В реальных примерах корпоративные хранилища могут содержать такие объемы данных, которые могут измеряться сотнями терабайт. Кроме того, часть данных будет исторической и будет реже использоваться в запросах.
В целом корпоративные хранилища поддерживают партиционирование — разбиение данных на части по определенному признаку и хранение похожих частей рядом для оптимизации обработки. Чтобы дополнительно оптимизировать такой формат хранения, DWS поддерживает перенос исторических (холодных) партиций в сервис объектного хранения Object Storage Service (OBS).
Чтобы воспользоваться «холодным» хранилищем, нужно создать новую схему хранения данных:
в ней будет использоваться денормализованная схема из предыдущего примера;
будет добавлено партиционирование данных по годам;
данные за последние три года будут считаться актуальными, а все остальные будут помещаться в холодное хранилище.
По умолчанию для каждого кластера Data Warehouse Service создается пространство в OBS под названием default_obs_tbs, которое может быть использовано для хранения холодных данных.
Чтобы создать новую схему данных и разметить партиции в соответствии с данными из колонки «timestamp», выполните запрос:
CREATE SCHEMA test4 AUTHORIZATION dbadmin;CREATE TABLE test4.ratings (movieId INTEGER,title VARCHAR(255) NOT NULL,genres VARCHAR(500) NOT NULL,userId INTEGER,rating double precision,timestamp timestamp) WITH (ORIENTATION = COLUMN, STORAGE_POLICY = "HPN:3", COLD_TABLESPACE='default_obs_tbs')DISTRIBUTE BY HASH(movieId)PARTITION BY RANGE(timestamp)(PARTITION P1 VALUES LESS THAN('1995-01-01'),PARTITION P2 VALUES LESS THAN('1996-01-01'),PARTITION P3 VALUES LESS THAN('1997-01-01'),PARTITION P4 VALUES LESS THAN('1998-01-01'),PARTITION P5 VALUES LESS THAN('1999-01-01'),PARTITION P6 VALUES LESS THAN('2000-01-01'),PARTITION P7 VALUES LESS THAN('2001-01-01'),PARTITION P8 VALUES LESS THAN('2002-01-01'),PARTITION P9 VALUES LESS THAN('2003-01-01'),PARTITION P10 VALUES LESS THAN('2004-01-01'),PARTITION P11 VALUES LESS THAN('2005-01-01'),PARTITION P12 VALUES LESS THAN('2006-01-01'),PARTITION P13 VALUES LESS THAN('2007-01-01'),PARTITION P14 VALUES LESS THAN('2008-01-01'),PARTITION P15 VALUES LESS THAN('2009-01-01'),PARTITION P16 VALUES LESS THAN('2010-01-01'),PARTITION P17 VALUES LESS THAN('2011-01-01'),PARTITION P18 VALUES LESS THAN('2012-01-01'),PARTITION P19 VALUES LESS THAN('2013-01-01'),PARTITION P20 VALUES LESS THAN('2014-01-01'),PARTITION P21 VALUES LESS THAN('2015-01-01'),PARTITION P22 VALUES LESS THAN('2016-01-01'));insert into test4.ratings SELECT m.movieId, m.title, m.genres, r.userId, r.rating, to_timestamp(cast(r.timestamp as decimal))::date FROM obs.movies m left join obs.ratings r on m.movieId = r.movieId where r.timestamp is not null;
Когда запрос будет выполнен, можно посмотреть как партиции распределились между горячим и холодным слоем. Для этого выполните команду:
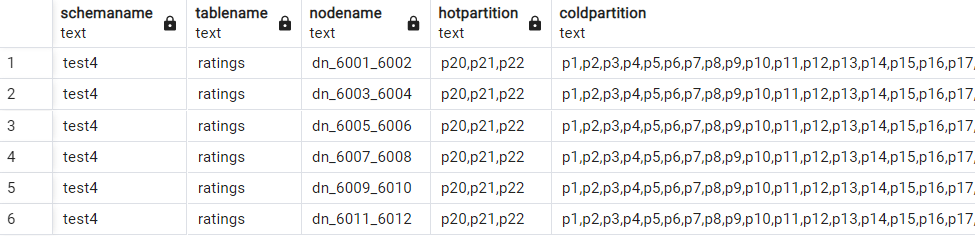
select * from pg_catalog.pg_lifecycle_table_data_distribute('test4.ratings');
В выводе видно, что данные за последние годы хранятся в DWS, а остальные в холодном хранилище:
Такая реализация позволяет сгружать исторические данные в более дешевый тип хранилища, что позволяет оптимизировать затраты на сервис DWS.
Ограничение доступных пользователю ресурсов
В реальных ситуациях с корпоративными хранилищами данных всегда взаимодействует несколько пользователей или систем. Иногда может возникнуть необходимость снизить выделяемые ресурсы для части запросов. Например, нужно, чтобы запросы от системы отчетности выполнялись с использованием всех ресурсов, но при этом аналитики не должны своими запросами заблокировать серверы, используя все его ресурсы.
Для решения подобной задачи в Data Warehouse Service можно создать отдельные очереди с ограниченными ресурсами и направить в них запросы от определенных пользователей.
Для тестирования нужно создать дополнительного пользователя, у которого будут ограничены доступы, и проверить производительность запросов, которые уже выполнялись ранее.
Чтобы создать пользователя с правами на работу со схемой «test2», выполните SQL-запрос:
CREATE USER slow_user WITH PASSWORD 'Str0ngP@ssw0rd';GRANT ALL PRIVILEGES ON SCHEMA test2 TO GROUP slow_user;GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA test2 TO GROUP slow_user;
Созданного пользователя нужно прикрепить к отдельной очереди, у которой будут ограничения на ресурсы. Чтобы создать очередь:
В левом верхнем углу консоли управления нажмите Homepage.
В списке сервисов выберите Data Warehouse Service.
Нажмите на название кластера.
В левом меню перейдите в раздел Workload.
Напротив Workload Queue нажмите
 .
.В поле Name задайте название очереди. Например slow_queue.
В поле CPU Share(%) введите 5.
В поле CPU Limit(%) введите 5.
В поле Memory Resource (%) введите 5.
Остальные параметры оставьте без изменений и нажмите Ok.
Выберите созданную очередь.
В разделе User Association нажмите Add:
Отметьте пользователя slow_user и нажмите OK.
Пользователь добавлен в очередь. Чтобы проверить быстродействие кластера при работе от имени пользователя slow_user, добавьте в pgAdmin еще один сервер, только в качестве пользователя укажите slow_user, а в качестве пароля Str0ngP@ssw0rd.
Чтобы увидеть разницу в производительности, откройте окно запросов для базы данных movies и выполните усложненный запрос. С помощью него можно получить название фильма, количество оценивших его пользователей и рейтинг:
select title, count(distinct userId) as number_of_user, avg(rating)from test2.movies m left join test2.ratings r on m.movieId = r.movieIdgroup by title
Результаты выполнения запроса, полученные при разработке практической работы:
пользователь dbadmin — 6 с;
пользователь slow_user — 9,6 с.
Даже на таком небольшом объеме данных при сложных запросах заметна разница в длительности выполнения запроса в зависимости от выделенных ресурсов.