Препроцессинг, или предварительная обработка данных, готовит их к анализу или обучению, повышает точность работы алгоритмов.
На GPU при помощи библиотеки RAPIDS
Используем образ cr.ai.cloud.ru/data-hub/jupyter-rapids-ai:latest:
client_lib.Job(base_image='cr.ai.cloud.ru/data-hub/jupyter-rapids-ai:latest',script='preprocessing.py',n_workers=1, instance_type='your instance_type')
Для получения значения instance_type воспользуйтесь инструкцией.
Пример 1. Использование одиночного GPU для препроцессинга
Использование GPU значительно ускоряет препроцессинг данных, ниже представлен график, показывающий во сколько раз 1 GPU быстрее 1 CPU по основным категориям обработки данных.
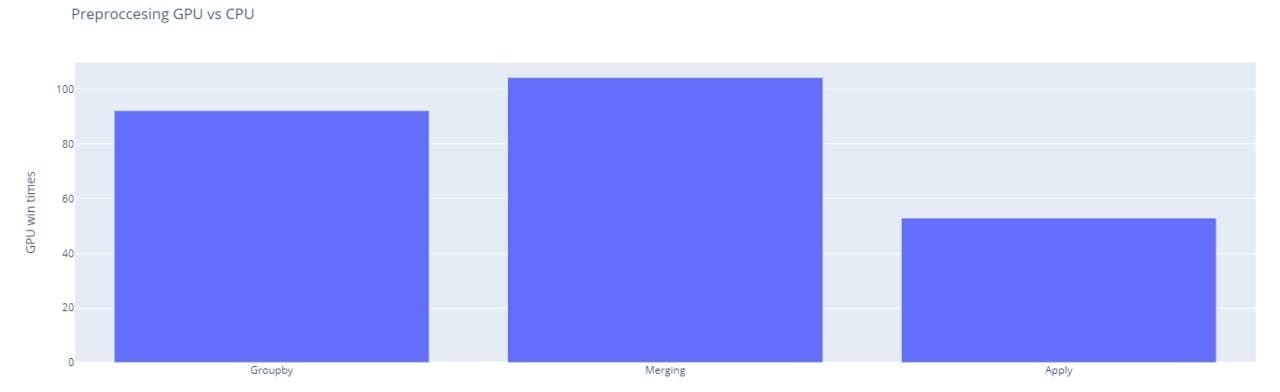
Запуск тестовой задачи:
client_lib.Job(base_image='cr.ai.cloud.ru/data-hub/jupyter-rapids-ai:latest',script='preprocessing.py',n_workers=1, instance_type='your instance_type')
Для получения значения instance_type воспользуйтесь инструкцией.
Тестовый скрипт preprocessing.py:
import cudfimport pandas as pdimport timefrom mpi4py import MPIimport cupy as cpimport numpy as npimport warningswarnings.filterwarnings('ignore')if __name__ == '__main__':comm = MPI.COMM_WORLDif comm.rank == 0:rand1 = np.random.randint(low=0, high=int(1e7), size=int(3e7))rand2 = np.random.random(size=int(3e7))rand3 = np.random.random(size=int(3e7))pdf = pd.DataFrame()pdf['a'] = rand1pdf['b'] = rand2pdf['c'] = rand3gpu_rand1 = cp.random.randint(low=0, high=int(1e7), size=int(3e7))gpu_rand2 = cp.random.random(size=int(3e7))gpu_rand3 = cp.random.random(size=int(3e7))gdf = cudf.DataFrame()gdf['a'] = gpu_rand1gdf['b'] = gpu_rand2gdf['c'] = gpu_rand3del gpu_rand1, gpu_rand2, gpu_rand3, rand1, rand2, rand3start_time = time.time()pdf.groupby('a')print(f'CPU groupby time = {round(time.time() - start_time, 3)} sec')start_time = time.time()gdf.groupby('a')print(f'GPU groupby time = {round(time.time() - start_time, 3)} sec')start_time = time.time()pdf = pdf.merge(pdf, on=['a'])print(f'CPU merge time = {round(time.time() - start_time, 3)} sec')start_time = time.time()gdf = gdf.merge(gdf, on=['a'])print(f'GPU merge time = {round(time.time() - start_time, 3)} sec')def my_udf(x):return (x ** 2) - xstart_time = time.time()pdf['d'] = pdf['a'].apply(my_udf)print(f'CPU apply time = {round(time.time() - start_time, 3)} sec')start_time = time.time()gdf['d'] = gdf['a'].applymap(my_udf)print(f'GPU apply time = {round(time.time() - start_time, 3)} sec')pdf['d'] = pdf['a'].apply(my_udf)print(f'CPU apply time = {round(time.time() - start_time, 3)} sec')start_time = time.time()gdf['d'] = gdf['a'].applymap(my_udf)print(f'GPU apply time = {round(time.time() - start_time, 3)} sec')
Пример 2. Распределенный препроцессинг в рамках одного DGX
Для решения такого рода задач необходимо выставить количество процессов на один воркер (processes_per_worker) и количество воркеров в 1. Создание дополнительных процессов и воркеров по количеству GPU обеспечивает утилита LocalCudaCluster из пакета dask_cuda.
client_lib.Job(base_image='cr.ai.cloud.ru/data-hub/jupyter-rapids-ai:latest',script='preprocessing.py',n_workers=1, instance_type='your instance_type',processes_per_worker=1)
Для получения значения instance_type воспользуйтесь инструкцией.
Пример простого скрипта, формирующего синтетическую выборку на GPU и выполняющего расчеты распределенно, приведен ниже.
preprocessing.py:
import cudffrom dask.distributed import Clientfrom dask_cuda import LocalCUDAClusterimport daskimport dask_cudfimport cupy as cpimport warningswarnings.filterwarnings('ignore')if __name__ == '__main__':cluster = LocalCUDACluster()client = Client(cluster)def make_cudf_dataframe(nrows=int(1e8)):cudf_df = cudf.DataFrame()cudf_df['a'] = cp.random.randint(low=0, high=1000, size=nrows)cudf_df['b'] = cp.random.randint(low=0, high=1000, size=nrows)cudf_df['c'] = cp.random.random(nrows)cudf_df['d'] = cp.random.random(nrows)return cudf_dfdelayed_cudf_dataframe = [dask.delayed(make_cudf_dataframe)() for i in range(20)]ddf = dask_cudf.from_delayed(delayed_cudf_dataframe)ddf.groupby(['a', 'b']).agg({'c': ['sum', 'mean']}).compute()client.close()cluster.close()
Пример 3. Распределенный препроцессинг
Для использования библиотек rapids в интерактивном режиме в рамках Jupyter Server необходимо использовать образ с библиотекой rapids из DataHub. С примерами использования можно ознакомиться как на сайте Rapids, так и на нашем Github.