Сервис мониторинга позволяет получать информацию о производительности ресурсов в AI Agents и включает в себя следующие дашборды:
Каждый дашборд поддерживает следующие настройки и опции:
Выбор периода сбора данных. По умолчанию отображаются данные за последние 2 часа.
Выбор интервала автообновления данных. По умолчанию обновляются каждые 5 минут.
Выгрузка графика в PNG-файл.
Просмотр графика в развернутом режиме.
Сервисные дашборды AI Agents
Для мониторинга производительности AI-агентов, агентных систем и MCP-серверов преднастроены отдельные сервисные дашборды.
Сервисный дашборд для мониторинга AI-агентов доступен в личном кабинете в разделе Мониторинг → Дашборды → Сервисные → AI Agents - Агент. Чтобы увидеть данные о состоянии AI-агена, выберите его и перейдите на вкладку Мониторинг.
На сервисном дашборде временной интервал анализа в виджетах равен одной минуте.
Для AI-агентов преднастроены следующие виджеты и метрики, из которых они состоят:
Название виджета, Единица измерения | Название метрики | Описание |
|---|---|---|
Потребление памяти, ГБ | ai_agents:system:cpu:workcload_info | Объем оперативной памяти, потребляемый агентом. |
Потребление CPU, % | ai_agents:system:cpu:workcload_info | Потребление вычислительных ресурсов агентом. |
Количество экземпляров, шт | ai_agents:system:online | Количество запущенных агентов на текущий момент. Может изменяться при масштабировании. |
Пропускная способность, Бит/с | ai_agents:system:request:bandwidth | Объем данных, переданных по сети. |
Время ответа, с | ai_agents:system:request:http_latency_bucket | Время от получения запроса до отправки ответа. |
Запросов в секунду (RPS) по кодам ответа, шт/с | ai_agents:system:request:http_status | Количество успешных и ошибочных запросов, обработанных агентом. |
Успешно обработанных запросов, шт/с | ai_agents:system:request:http_status | Количество успешно обработанных запросов. |
Ошибочных запросов, шт/с | ai_agents:system:request:http_status | Количество запросов, обработанных с ошибкой. |
Внутренние ошибки,шт/с | ai_agents:system:request:http_status | Количество запросов, которые агент не смог обработать из-за внутренних ошибок. |
Пользовательские дашборды для AI Agents
Вы можете создать и настроить дашборд с виджетами по своему усмотрению.
При создании виджета укажите ai_agents:system: в поле Запрос.
Для создания виджетов доступны следующие метрики:
Метрика | Описание |
|---|---|
ai_agents:system:cpu:workcload_info | Отображает текущую загрузку центрального процессора (CPU). |
ai_agents:system:gpu:workcload_info | Отображает текущую загрузку графического процессора (GPU). |
ai_agents:system:memory:workcload_info | Отображает объем используемой оперативной памяти (RAM). |
ai_agents:system:online | Отображает работоспособность сервиса на текущий момент. |
ai_agents:system:request:bandwidth | Отображает скорость передачи данных. |
ai_agents:system:request:bytes_bucketai_agents:system:request:bytes_countai_agents:system:request:bytes_sum | Отображают размер запросов и ответов. Используются совместно для построения гистограмм и расчета среднего объема передаваемых данных. |
ai_agents:system:request:duration_milliseconds_bucketai_agents:system:request:duration_milliseconds_countai_agents:system:request:duration_milliseconds_sum | Отображают время обработки запроса внутри приложения. Используются совместно для анализа производительности и построения распределения длительности обработки. |
ai_agents:system:request:http_latency_bucketai_agents:system:request:http_latency_countai_agents:system:request:http_latency_sum | Отображают общее время между отправкой запроса и получением ответа. Используются совместно для оценки времени отклика сервиса. |
ai_agents:system:request:http_status | Отображает количество запросов с разбивкой по кодам HTTP-ответа (2xx, 4xx, 5xx и др.). |
ai_agents:system:requests_total | Отображает общее количество запросов, полученных сервисом с момента запуска. |
Пример создания виджета «95-й перцентиль времени ответа»
Виджет «95-й перцентиль времени ответа» — один из ключевых индикаторов производительности сервиса. Он отражает, насколько быстро обрабатываются запросы для большинства пользователей. В отличие от среднего времени, p95 не искажается редкими длительными запросами и точнее характеризует реальный пользовательский опыт.
Для создания виджета:
Откройте созданый дашборд.
Нажмите Создать виджет.
Выберите тип отображения данных — Временной ряд.
Укажите название — 95-й перцентиль времени ответа.
В поле Запрос укажите:
histogram_quantile(0.95, sum(rate(ai_agents:system:request:duration_milliseconds_bucket[5m])) by (le))Где:
histogram_quantile(0.95, ...) — основная функция: находит значение времени, ниже которого находится 95% всех запросов.
...duration_milliseconds_bucket — метрика для сортировки запросов по скорости с разбивкой на корзины (buckets).
sum(...) by (le) — агрегация частоты по всем экземплярам сервиса с группировкой по метке le. Метка le указывает верхнюю границу каждой корзины.
rate(...[5m]) — вычисляет частоту запросов, попадающих в каждую корзину (buckets).
[5m] — определяет временной интервал анализа — последние 5 минут.
В поле Легенда укажите 95-й перцентиль (p95).
Остальные параметры настройте по своему усмотрению или оставьте по умолчанию.
Нажмите Сохранить.
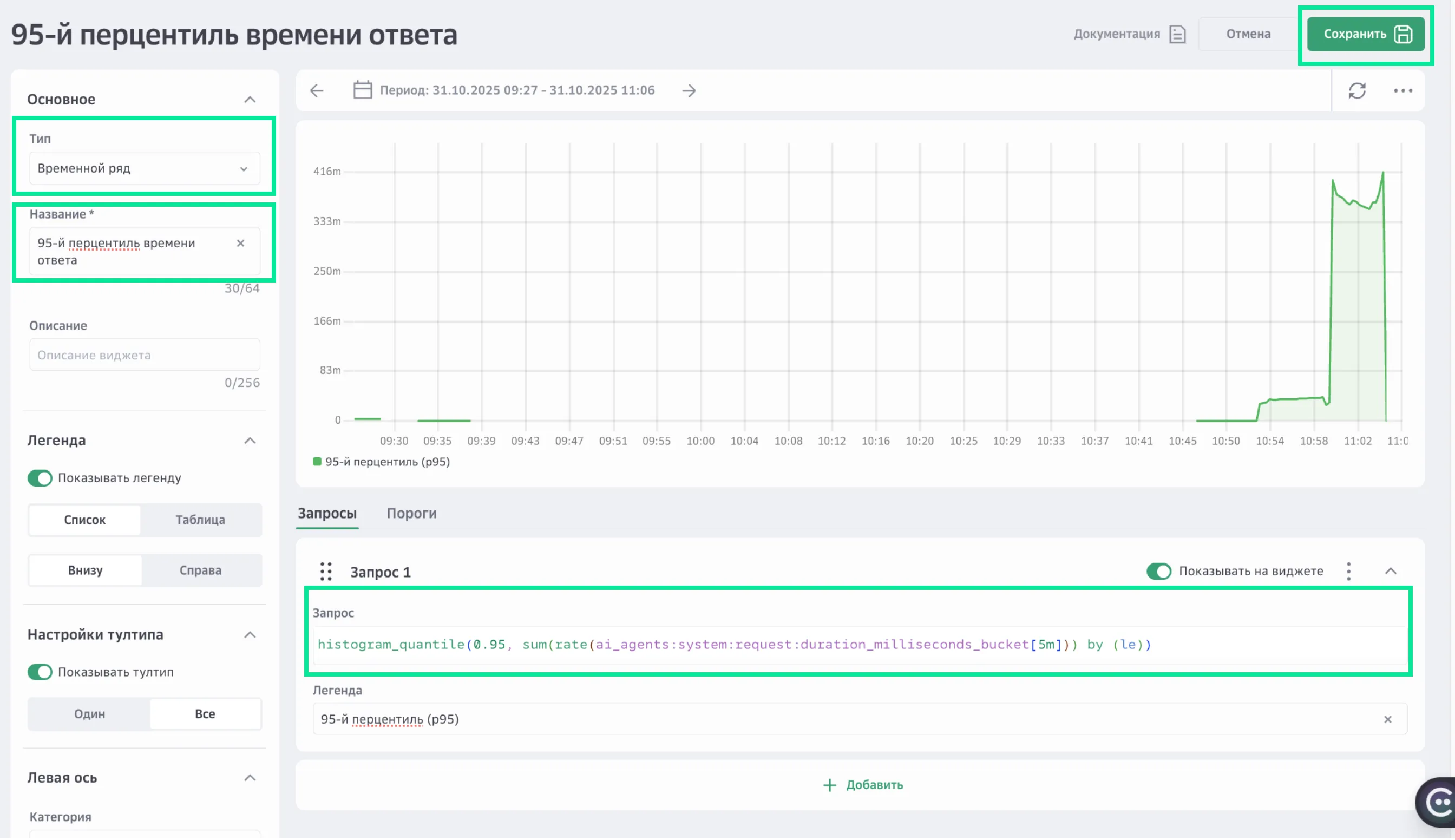
Созданный виджет отобразится на вашем дашборде.
Вы можете использовать этот виджет как инструмент мониторинга производительности. Он поможет оперативно выявлять регрессии после релизов и поддерживать высокое качество сервиса.
Подробные инструкции о работе с дашбордами читайте в документации сервиса «Мониторинг»:
Сервисные дашборды — работа с преднастроенными дашбордами.
Пользовательские дашборды — создание пользовательских дашбордов с кастомными виджетами и метриками.
Алерты — настройка алертов и уведомлений об изменении в метриках.
Вычисляемые метрики — создание сложных запросов на основе существующих метрик.