Мониторинг приложений в облачном Kubernetes: обзор инструментов и инструкция по настройке
Любое современное приложение, работающее в продакшене, нуждается в постоянном мониторинге и сборе метрик. Метрики позволяют оценивать как технические характеристики (скорость работы, задержки ответов), так и бизнесовые (взаимодействие пользователей, эффективность процессов). Своевременное отслеживание этих показателей напрямую влияет на устойчивость сервисов, стабильность и успех бизнеса.
Как собирать метрики в приложениях, работающих в облачных K8s, и какие инструменты для этого использовать — разберем в этой статье.


Классический стек мониторинга с Prometheus
Prometheus является самым популярным решением для мониторинга и промышленным стандартом отрасли.
 По результатам опроса Cloud Native Computing Foundation, 73% компаний используют его в продакшене и еще 12% рассматривают его внедрение
По результатам опроса Cloud Native Computing Foundation, 73% компаний используют его в продакшене и еще 12% рассматривают его внедрениеЭта система получила широкое распространение благодаря нескольким особенностям:
Гибридная модель сбора данных. Prometheus сочетает pull-модель (основной метод) с push-механизмом через PushGateway, что позволяет работать в Kubernetes и Serverless-средах. Это критично для динамичных инфраструктур, где сервисы могут быть непостоянными.
Многомерная модель данных. Метки (labels) в временных рядах позволяют детализировать анализ, например, разбивать метрики по версии приложения, зоне доступности или статусу HTTP-ответа. Это упрощает диагностику проблем в микросервисных архитектурах.
Интеграция с Kubernetes. Kube-Prometheus-Stack автоматизирует развертывание через оператор, предоставляя готовые дашборды для мониторинга:
потребление ресурсов подов и нод;
статусы развертываний (deployments/statefulsets);
автоматическое обнаружение сервисов.
Экосистема инструментов. Возможности Prometheus легко расширяются с помощью дополнительных инструментов, таких как:
Grafana: визуализация метрик через готовые шаблоны;
Alertmanager: гибкая система алертинга с маршрутизацией уведомлений;
Exporters: большое количество готовых сборщиков метрик (Node Exporter, Blackbox Exporter и др.) как от Prometheus, так и от сторонних разработчиков.
Для работы Prometheus потребуются выделенные ресурсы — примерно 2 CPU и 2 ГБ RAM для обработки 1 млн метрик, а также команда специалистов для поддержки системы.
Решения от облачных провайдеров
Облачные провайдеры, как правило, предоставляют собственные инструменты мониторинга, интегрированные в общую систему. Они позволяют быстро и с минимальными усилиями подключить сбор метрик из приложений, запущенных в их инфраструктуре, в том числе в K8s, настроить их отображение и оповещения на основе полученных данных (алерты). Все процессы проводятся в режиме «одного окна», нет необходимости устанавливать дополнительные приложения, все доступно в личном кабинете.
Плюсы такого решения: низкая цена и нагрузка на команду. Нет необходимости следить за работоспособностью мониторинга — за это отвечает провайдер, а стоимость на порядки ниже. Например, стоимость 1 млн метрик в Google Cloud составляет до $0.06. При этом для обработки 1 млн метрик нам потребуется дополнительно 1 vCPU и 1 Гб RAM.
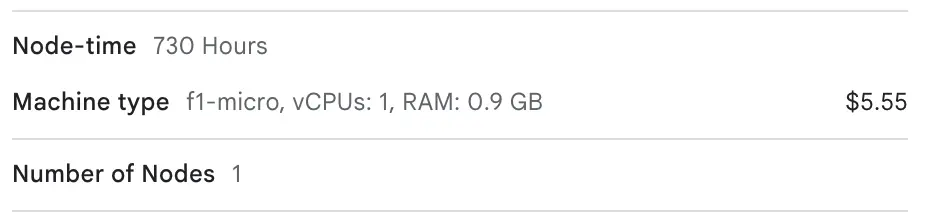 Стоимость рабочего узла с такими параметрами в Google Kubernetes Engine составит $5.55 в месяц
Стоимость рабочего узла с такими параметрами в Google Kubernetes Engine составит $5.55 в месяцИз минусов можно отметить меньшую гибкость настройки. В случае с самостоятельной установкой вы ограничены только пределами возможностей инструмента и своей фантазией, а у облачного провайдера могут быть лимиты на количество метрик, дашбордов, алертов, другие количественные ограничения, а также сокращенный набор параметров настройки. Однако, для большинства приложений их будет вполне достаточно, а часть ограничений можно будет снять за дополнительную плату.
Сторонние SaaS-сервисы
Существуют SaaS-сервисы, которые предоставляют услуги сбора, визуализации и аналитики метрик. Например:
Datadog
Sematext
Dynatrace
New Relic
Эти сервисы будут удобны, если нужно построить мониторинг для гибридной системы, которая включает в себя разных облачных провайдеров и self-hosted решения. Некоторые из них даже предоставляют аналитику показателей с помощью AI.
Однако, у них есть и недостатки:
Ограниченный набор поддерживаемых облачных провайдеров, преимущественно зарубежных.
Работают в основном с техническими метриками (нагрузка, сеть, состояние машин, узлов и компонентов и т.д.), не всегда есть возможность собирать метрики приложения.
Стоимость значительно выше, чем собственные решения облачных провайдеров.
Как настроить мониторинг в облаке Cloud.ru
Мы рассмотрели несколько вариантов, как можно организовать мониторинг вашего приложения, запущенного в облачном K8s — выбор за вами. А если вы решили, что вам больше всего подходит мониторинг от провайдера и ваш провайдер — Cloud.ru, то сейчас расскажу, как быстро и просто настроить мониторинг приложения в Evolution Managed Kubernetes.

Этап 1. Установка плагинов в кластер. Плагины можно установить на этапе создания нового кластера, а можно установить в существующий, если не сделали этого раньше.
При создании кластера важно включить параметр «Мониторинг», либо установить Kube State Metric и Node Exporter через раздел «Плагины» существующего кластера.
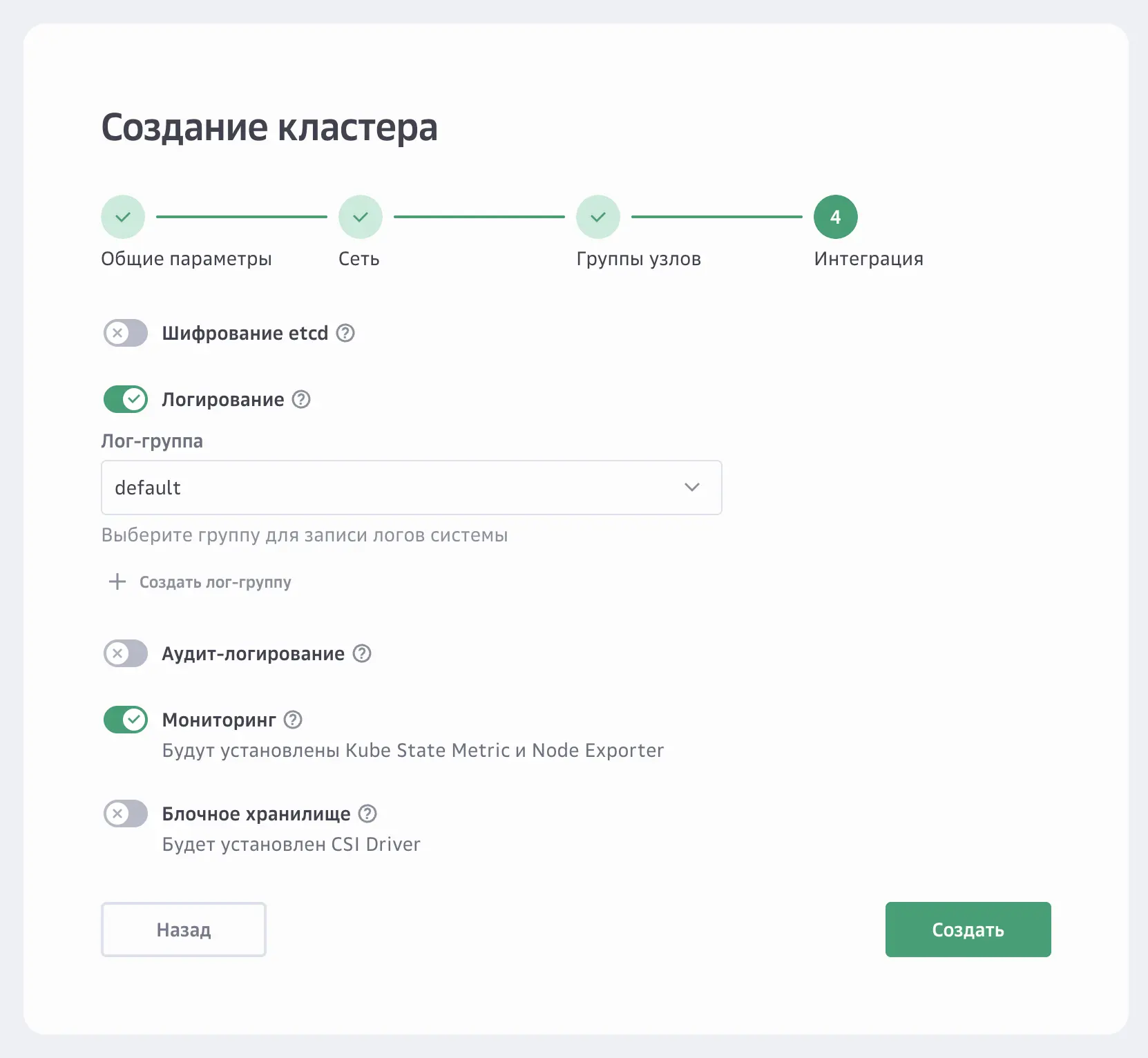 Создание кластера в личном кабинете Cloud.ru
Создание кластера в личном кабинете Cloud.ruЭти плагины обеспечат сбор информации о работе узлов кластера, а также его ресурсов: pods, deployments, services и т.д.
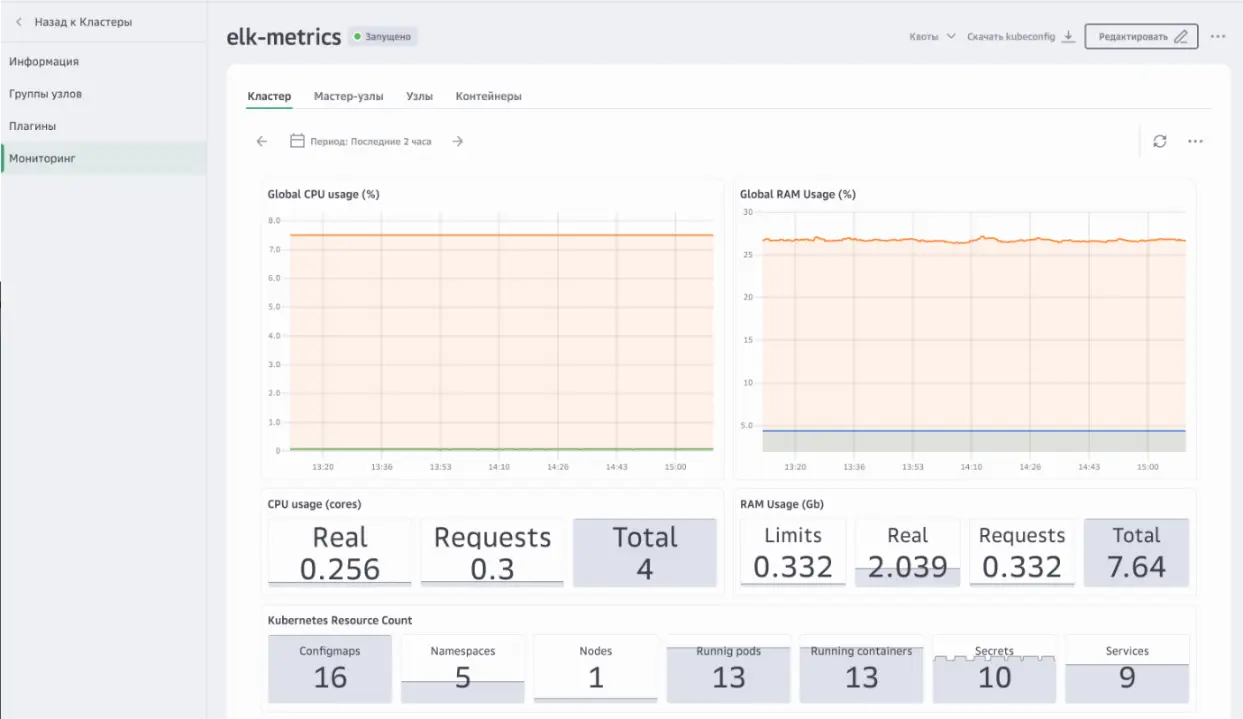 После их установки вы можете видеть метрики кластера в разделе «Мониторинг»
После их установки вы можете видеть метрики кластера в разделе «Мониторинг»Далее в разделе «Плагины» установим vmagent, который собирает метрики из подов, в которых запущены наши приложения. Он совместим с форматами Prometheus и Victoria Metrics, что позволяет использовать привычные библиотеки для мониторинга в коде приложений.
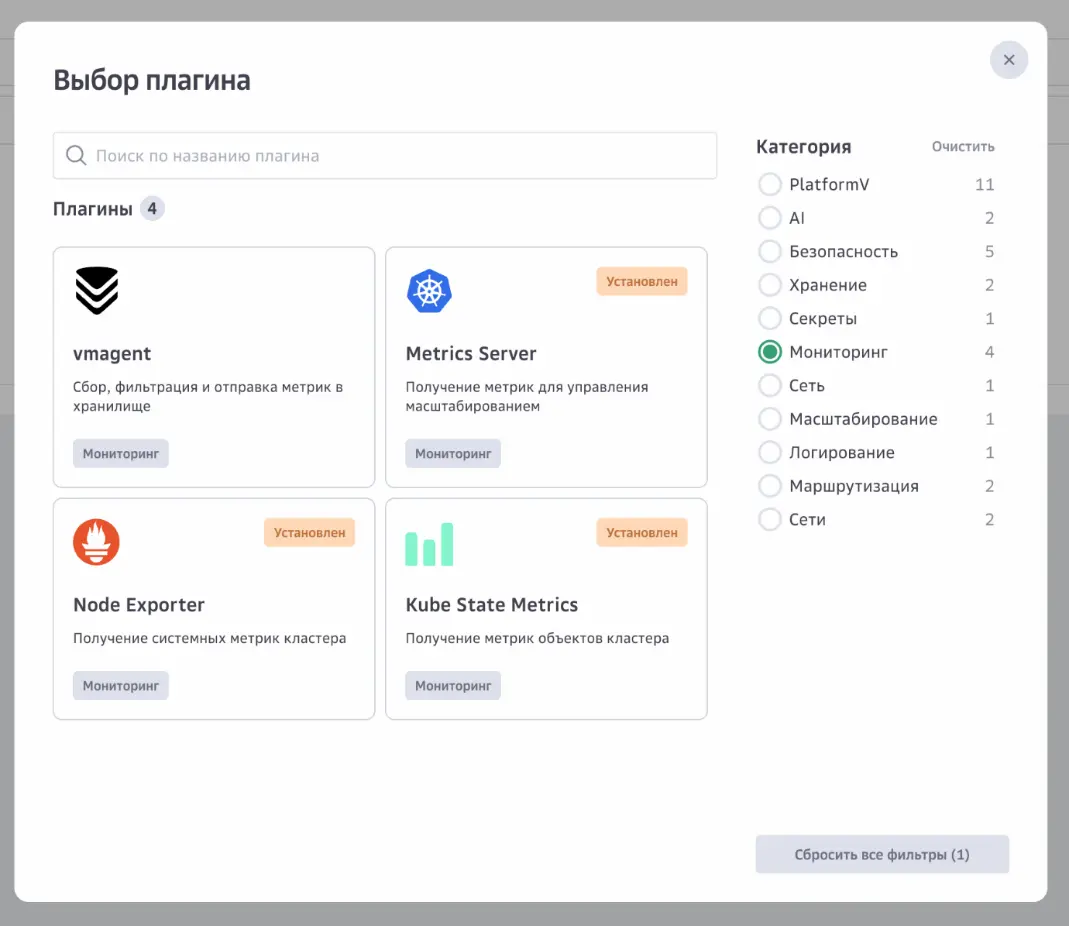 Выберите категорию «Мониторинг» в разделе «Плагины» и перейдите к vmagent
Выберите категорию «Мониторинг» в разделе «Плагины» и перейдите к vmagentЭтап 2. Деплой приложения. Теперь можем задеплоить наше приложение. Я собрал простой HTTP-сервер и клиент для него, который с определенной периодичностью выполняет запрос, и добавил в них запись метрик количества и времени на каждый запрос. Это минимальные возможности, но их хватит для демонстрации.
Чтобы плагин начал собирать метрики, добавим аннотации в секцию template.metadata.annotations:
Приложение запущено, можно перейти к следующему этапу.
Этап 3. Настройка дашборда. Настройка виджетов дашбордов очень похожа на использование сервиса Grafana, так что, если вы знакомы с этим инструментом, вы без труда справитесь и здесь. Поддерживаются языки запросов PromQL и MetricsQL.
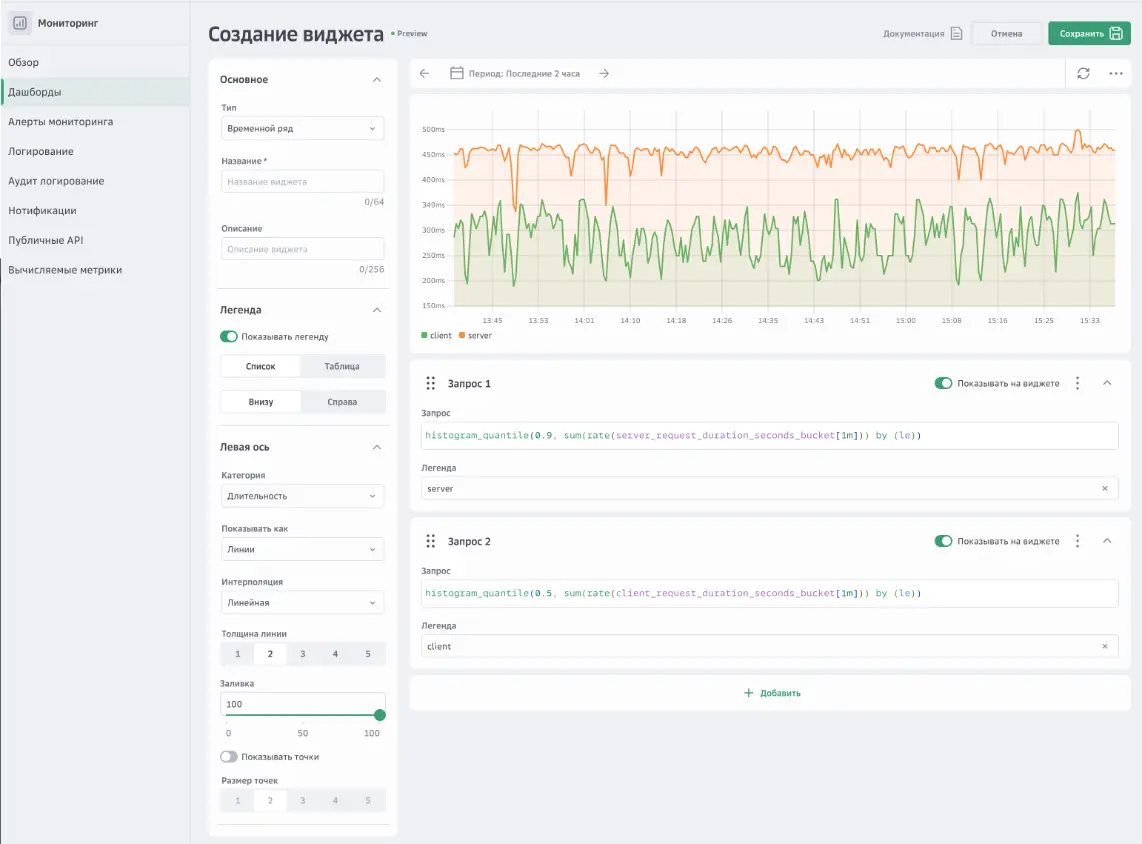 Данные появились в облачном мониторинге, значит все настроено верно, можем перейти к настройке алертов
Данные появились в облачном мониторинге, значит все настроено верно, можем перейти к настройке алертовЭтап 4. Настройка алертов. В разделе «Алерты мониторинга – Правила алертов» добавим новое правило.
Кроме основных параметров срабатывания, можно также настроить автозакрытие алерта и дополнительные аннотации. Сохраняем правило и ждем, пока алерт сработает. Приложение имитирует задержки в целях демонстрации.
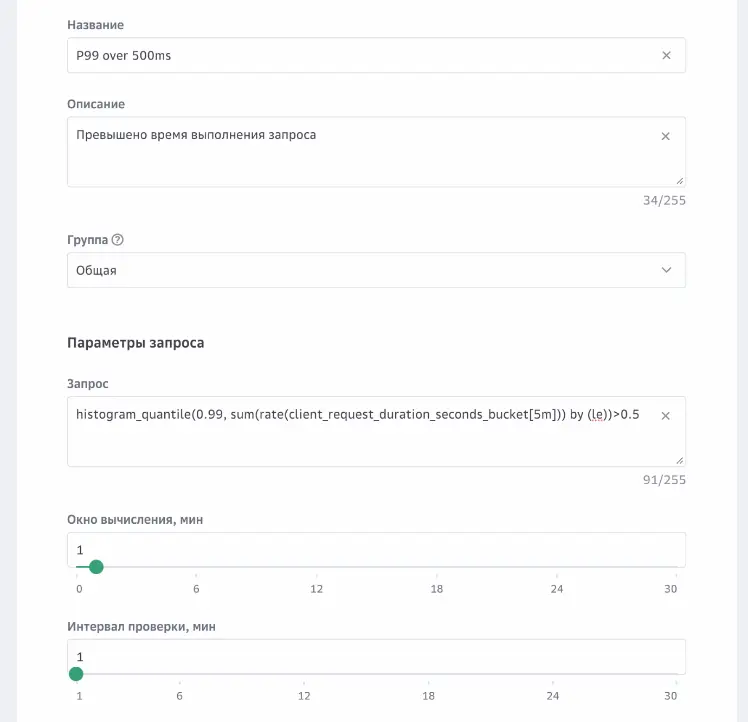 Создание правила
Создание правилаАлерт сработал, теперь мы можем подтвердить его получение или завершить, если проблема устранена, а автоматическое завершение не было включено.
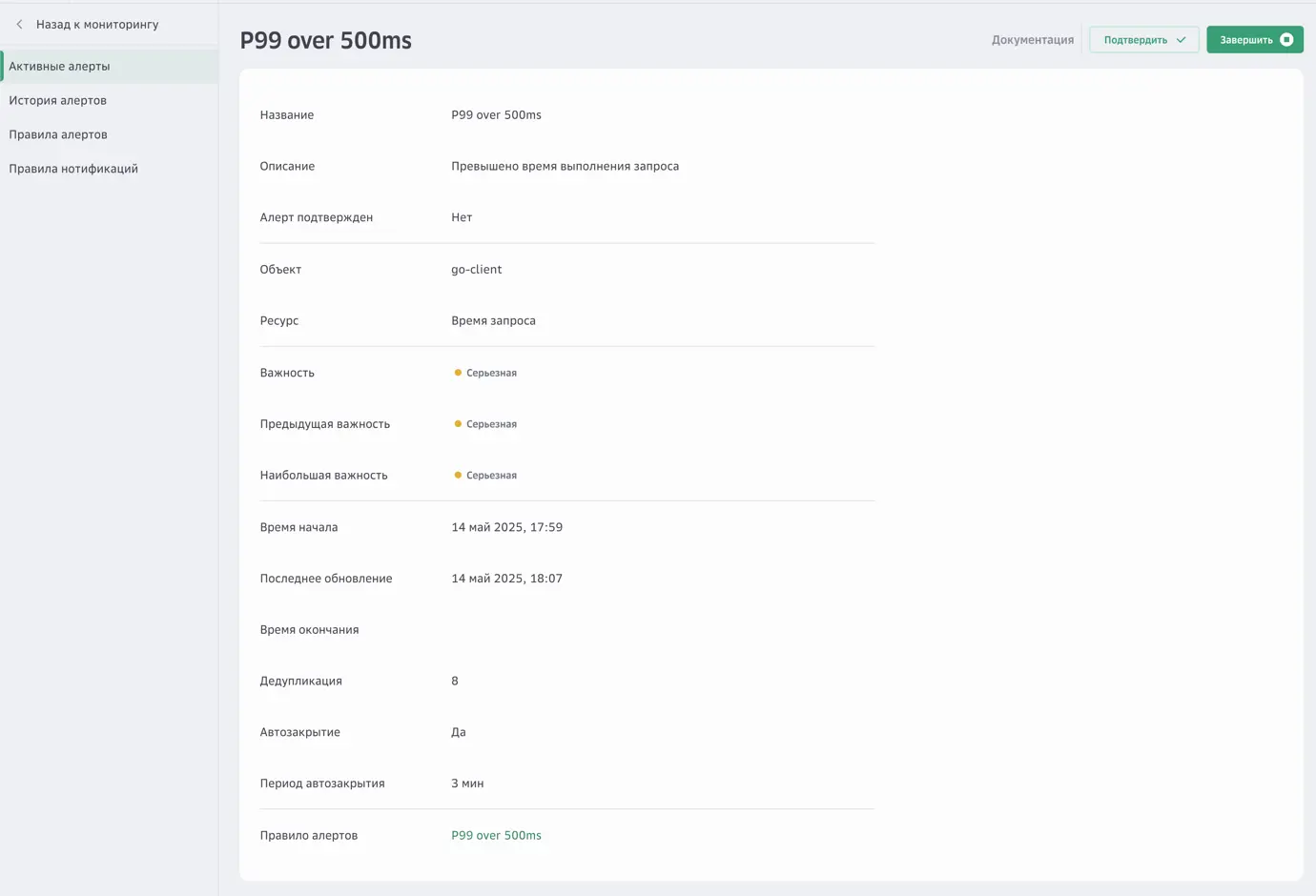
Для настройки доставки сообщений об алертах необходимо настроить сервис нотификаций. Его настройка выходит за рамки этой статьи, но кратко расскажу: в этом сервисе создаются списки рассылок с контактами е-mail или Telegram, а также можно использовать HTTP Webhooks.
Вся настройка мониторинга в личном кабинете Cloud.ru займет у вас около трех минут. В результате вы получите непрерывный контроль технических параметров кластера с преднастроенными дашбордами, сбор метрик приложения и первый пользовательский дашборд. А если вы сейчас в поиске решения для автоматизированной работы с контейнерами, можете протестировать сервис Evolution Managed Kubernetes и сразу настроить мониторинг по этой инструкции.